Le curating algorithmique
« En 1957, Robert A. Dahl donnait du concept de pouvoir la définition suivante : “A exerce un pouvoir sur B dans la mesure où il obtient de B une action que B n’aurait pas effectuée autrement. ” […] La manifestation du pouvoir la plus directe est la force coercitive ou “puissance dure”. […] L’emprisonnement. Un revolver pointé sur vous, ou même le fait de savoir ou de supposer que votre opposant a un revolver. […] Des situations au cours desquelles vous, B, faites face aux conséquences directes et négatives de votre possible refus d’obéir à A. La “puissance douce”, à l’opposé, pousse B à agir comme A le souhaite parce que B estime qu’il est intéressant (et donc profitable) d’être comme A. C’est le pouvoir de la séduction, de la persuasion, de l’image, et de la marque. La puissance douce résulte en un changement de comportement de B sous l’influence de A, sans qu’aucun acte ou aucune menace d’emploi de la force ait été nécessaire1. »
« Tout procédé technologique comporte un degré d’abstraction. […] L’ abstraction implique une relation dans laquelle le fait que l’utilisateur se conforme à cette abstraction bénéficie au fournisseur au point que A obtient de B une action que B n’aurait pas effectuée autrement2. » L’abstraction est ce derrière quoi l’on se retranche lorsque l’on parle du cloud, des réseaux, mais aussi par exemple de l’agro-alimentaire ou des laboratoires pharmaceutiques, elle peut être une manière de dissimuler quelque chose ou, plus simplement, de ne pas vouloir voir cette chose.
Les algorithmes sont des abstractions qui produisent des résultats concrets.
Les utilisateurs de Facebook génèrent environ 4 millions de like par minute3, et plus de 7 milliards par jour. 49% de ces utilisateurs affirment liker une page Facebook pour soutenir une marque qu’ils apprécient4. (Peut-on réfléchir une seconde à ce que signifie « soutenir une marque que l’on apprécie » ?)
Revenons rapidement sur le fonctionnement de tout cela.
Une grande partie de notre vie quotidienne est dorénavant médiée par des systèmes d’intelligence artificielle — systèmes dont l’intelligence dépend de l’ingestion de la plus grande quantité possible de données à notre sujet — que nous sollicitions un emploi, une nouvelle assurance santé ou un prêt, que nous achetions un billet de train, un livre ou des chaussures sur Internet, que nous réservions un Uber ou un appartement sur Airbnb, ou simplement que nous nous connections à notre boîte mail, à Facebook pour prendre des nouvelles d’un ami, à Twitter pour prendre des nouvelles du monde, à notre compte bancaire pour faire un virement, ou que nous contactions le service clientèle de notre opérateur téléphonique… (Les systèmes d’intelligence artificielle ne sont pas tous connectés à Internet, un fait que nous avons tendance à oublier).
L’on pourrait considérer ces algorithmes avec lesquels nous interagissons communément (« les indexeurs, les algorithmes de recommandation et de visualisation qui offrent aux usagers un sentiment de contrôle sur ces données. Ces mêmes algorithmes qui, pourtant, rendent le cloud utilisable, sont ceux qui définissent un “utilisateur” comme un flux de données à analyser et à cibler5 ») comme des processus oscillant entre puissance dure et puissance douce : dure parce qu’ils limitent clairement nos actions, comme « liker », et douce parce que nous nous y soumettons volontairement, comme lorsque nous « likons ». Ainsi que l’écrit Matteo Pasquinelli, « Deleuze a exprimé ce changement qui marque le passage de la société disciplinaire de Foucault aux “sociétés de contrôle” basées sur des “banques de données”. 6 » Et, effectivement, « les plateformes nous permettent d’agir de manière datafiée, pré-algorithmique » nous rappelait Carolin Gerlitz lors de la dernière rencontre de l’AoIR7. Oui, les algorithmes curatent ce que nous voyons chaque jour sur nos fils d’actualité, « décident » de combien de temps ce contenu reste visible et à qui il est montré. Pour eux, nous sommes un ensemble de données. Ni plus ni moins. Prenons l’exemple d’une carte de crédit. « Il n’y a souvent pas de limite de dépense préétablie associée à une carte et parce qu’un ordinateur détermine si une transaction est frauduleuse en la comparant aux dépenses que fait régulièrement le porteur de la carte, ce dernier n’a même pas à se faire de souci s’il se fait dérober sa carte. […] Quelque part, il y a un ordinateur qui calcule l’impact de chaque dépense et s’y ajuste en temps réel et, en retour, le porteur de la carte s’y ajuste lui aussi. “Vous” êtes un ensemble de motifs de dépenses. » Les algorithmes sont simplement une manière d’organiser et de traiter ces données qui nous définissent. Ils ne sont que des ensembles d’instructions. Ni plus ni moins.
Alors pourquoi semblent-ils gagner en pouvoir sur nous ? Parce que nous les habilitons à émettre des jugements9 et, en retour, ces jugements qu’ils produisent influent sur nos comportements en une autorégulation héritée du panoptisme benthamien mais, surtout, du contrôle deleuzien issu de la décentralisation du pouvoir que l’on croit percevoir dans l’infrastructure du réseau. Il ne s’agit donc pas simplement d’un confort que l’on pourrait trouver dans le fait de déléguer nos prises de décisions, mais d’une structure plus complexe de renvois d’influences qui opèrent de manière si discrète que l’on finit par les internaliser. Ce n’est donc plus la désormais classique question d’une filter bubble9 mais d’une normalisation des pratiques par l’habitude qui vient se poser. Nous pouvons ainsi supposer que les inférences et les prédictions produites par les systèmes algorithmiques ne vont pas rationaliser nos comportements mais au contraire, comme l’explique Antoinette Rouvroy, « dispenser les acteurs humains de toute une série d’opérations mentales (la représentation des faits, l’interprétation, l’évaluation, la justification, etc.) qui font partie du jugement rationnel, au profit d’une gestion systématique de manière à susciter des pulsions d’achat.11 » Car, si « la gouvernementalité algorithmique est nourrie essentiellement de “données brutes” en elles-mêmes asignifiantes (cette absence de signification étant d’ailleurs perçue comme un gage d’objectivité)”12, “ des décisions critiques sont prises non sur la base des données en elles-mêmes, mais sur la base des données analysées algorithmiquement.13 » Les algorithmes sont en effet des filtres et, tout comme les données, ne produisent pas directement de signification en eux-mêmes. C’est la manière dont ils sont utilisés et, surtout, dont leurs résulats sont interprétés qui importe. « Ainsi, l’utilité de chaque donnée dépend de la quantité des autres données avec lesquelles elle est susceptible d’être corrélée, plus que de sa densité en information. Même des données à très faible densité d’information (des données anonymes qui, individuellement, sont absolument triviales et asignifiantes), gagnent en utilité lorsque leur quantité croît. »14
Tout comme les données, les algorithmes sont ce que l’on en fait, ils sont définis par leur usage. Les questionnements critiques qui émergent sont donc évidemment qui les utilise mais aussi qui les élabore ?
Ainsi que le fait remarquer Kate Crawford, 80% à 90% des personnes employées dans ces centres d’ingénierie (qui sont principalement répartis entre les sept entreprises majeures dans le monde qui conçoivent les systèmes d’intelligence artificielle) sont des hommes, pour la grande majorité blancs et d’origine aisée. Des hommes qui donc « se ressemblent et pensent de manière semblable »15 en équipes dans lesquelles les minorités sont plus que sous-représentées. Et, comme « un système algorithmique n’est pas simplement du code et des données mais un assemblage d’acteurs humains et non humains — de code, de pratiques et de normes institutionnellement positionnées qui ont le pouvoir de créer, d’entretenir et de rendre signifiantes des relations entre des personnes et des données par des actions semi-autonomes et difficilement observables16 », la question qu’il est urgent de poser est celle du dépassement de la gouvernementalité algorithmique en elle-même et de l’examen de notre relation à elle pour cesser de la considérer comme le cœur du problème.
C’est ici que les artistes interviennent. En interrogeant ce qui est en jeu lorsque nous délégons un choix à une machine, en particulier dans un domaine aussi définitionnel de l’homme que l’art, (bien que cela semble une conséquence parfaitement directe du content curating de nos feeds Twitter, Facebook, Instagram, etc.), ils nous rappellent que la quantification générale qui préside à tout système algorithmique est en premier lieu une idée hautement criticable. Que Cameron MacLeod s’appuie sur un algorithme de sa création pour désigner les artistes qui figureront dans les expositions collectives qu’il organise ou que Jeremy Bailey en utilise un pour déterminer les œuvres qui seront présentées dans des expositions qu’il décrit comme personnalisées aux goûts d’un spectateur unique, tous deux investissent le curating — en tant qu’artistes — d’une dimension machinique qui ouvre un champ inédit de perspectives technologiques autant que philosophiques.
1 Metahaven, Black Transparency, The Right to Know in the Age of Mass Surveillance, 2015, Sternberg Press, p. 121.
2 Metahaven, op.cit., p. 127.
3 Données de 2015. Source: http://wersm.com/how-much-data-is-generated-every-minute-on-social-media/
4 Données de 2013. Source: http://marketingland.com/why-do-consumers-become-facebook-fans-49745
5 Tung Hui-Hu, A Prehistory of the Cloud, MIT Press, 2016, p.111.
6 Matteo Pasquinelli citant Gilles Deleuze, « Post-scriptum sur les sociétés de contrôle », L’autre journal, Mai 1990, dans son article “The Spike : On the Growth and Form of Pattern Police”, in Nervous Systems, Spector Books, 2016, p. 283.
7 Conférence annuelle de l’Association of Internet Researchers à Berlin, du 5 au 8 octobre 2016. Voir la discussion entre Carolin Gerlitz, Kate Crawford et Fieke Jansen intitulée “Who rules the internet?”: http://www.hiig.de/en/events/aoir-who-rules-the-internet/
8 Tung Hui-Hu, A Prehistory of the Cloud, op.cit., p. xv.
9 « La notion d’algorithme fait partie d’un vocabulaire plus large utilisé pour promouvoir une certaine rationalité basée sur les mérites du calcul, de la compétition, de l’efficience, de l’objectivité et sur le besoin d’être stratégique. […] Le pouvoir de l’algorithme n’est peut-être pas simplement dans le code mais dans la manière dont il est devenu une partie de la compréhension discursive de désirabilité et d’efficacité dans laquelle la mention des algorithmes fait partie d’un “code de normalisation” ». David Beer, « The social power of algorithms », in Information, Communication & Society, 20:1, 1-13, p.9. http://dx.doi.org/10.1080/1369118X.2016.1216147
10 Eli Pariser, The Filter Bubble: What the Internet Is Hiding from You, New York, Penguin Press, 2011. C’est Pariser qui, le premier, a théorisé cette hyper-personalisation du web, c’est-à-dire des moteurs de recherche, des réseaux sociaux et des fils d’actualité, peu après que Google ait commencé à ne pas fournir les mêmes résultats aux mêmes demandes incluant les mêmes termes de recherche pour des requêtes effectuées par des personnes différentes, à la fin de l’année 2009.
11 Antoinette Rouvroy dans un entretien avec Marie Dancer, TANK, n°15, hiver 2016.
12 Antoinette Rouvroy, “Le gouvernement algorithmique ou l’art de ne pas changer le monde”, 2016, non publié.
13 Frank Pasquale, The black Box society: The secret algorithms that control money and information. Cambridge, Harvard University Press, p.21.
14 Antoinette Rouvroy, “Des données et des hommes, droits et libertés fondamentaux dans un monde de données massives”, rapport à destination du Comité Consultatif de la Convention pour la protection des personnes au regard du traitement automatisé de données personnelles du Conseil de l’Europe, texte augmenté, p. 6.
15 “Artificial Intelligence is Hard to See: Social & ethical impacts of AI”, Kate Crawford en conversation avec Trevor Paglen, Berlin, 7 octobre 2016. https://www.youtube.com/watch?v=kX4oTF-2_kM
16 Mike Ananny, Kate Crawford, “Seeing without knowing: Limitations of the transparency ideal and its application to algorithmic accountability”, new media & society, 2016, p. 11. http://journals.sagepub.com/doi/full/10.1177/1461444816676645
17 L’expression a été créée par Antoinette Rouvroy.
Entretien avec Cameron MacLeod
Depuis déjà trois années essaiment entre Suède, Norvège et Lituanie des expositions collectives pour lesquelles les artistes n’ont pas été choisis par un curateur mais par un algorithme. L’on discute de ce programme, le Curatron, et de ses implications, techniques comme éthiques, avec son créateur, l’artiste canadien Cameron MacLeod.
Si un curateur humain utilise Curatron, est-il toujours un curateur selon vous ? Curatron est-il plutôt un outil pour curateurs ou une sorte de curateur algorithmique à part entière ?
Eh bien, tout dépend de la manière dont on définit un « curateur ».
Il faut quelqu’un pour initier une exposition qui utilise Curatron, il y a donc au moins un initiateur. La personne qui utilise Curatron fait une proposition à la communauté artistique incluant les paramètres suivants : la manière dont le groupe sera sélectionné mais aussi les ressources qui seront mises à la disposition de ces artistes (l’espace, le financement, la communication, etc.). Ce qui implique qu’un certain nombre de décisions soient prises avant que l’appel à candidatures soit lancé, et aussi après, selon les termes de la proposition. Certains penseront que le fait que les artistes participent au processus de sélection invalide la définition du curateur, tandis que d’autres verront la création de la proposition et l’organisation de l’exposition comme un acte curatorial. Cela dépend aussi de la manière dont l’initiateur se définit lui-même. Je n’ai pas d’avis particulier sur la question de savoir si utiliser Curatron est un geste curatorial ou non, mais si oui, Curatron peut aussi être considéré comme un outil pour les curateurs.
Comment l’accrochage se passe-t-il : les artistes décident-ils de tout par eux-mêmes, ensemble, ou s’appuient-ils sur le curateur de l’espace où l’exposition a lieu ?
Un groupe est donc sélectionné via un appel à projet ; la manière dont l’exposition est mise en place peut être soit la décision du groupe sélectionné, soit celle du curateur. Dans tous les cas, ceci est expliqué dans l’appel à projet, les artistes savent donc à quoi s’attendre. Par exemple, je pourrais écrire que le groupe devra produire une œuvre en commun, ce que la plupart des gens envisageraient comme un acte curatorial.
Nous avons connu toutes sortes de degrés d’implication des artistes dans les expositions que nous avons déjà organisées avec Curatron. Au départ, j’étais très présent, mais désormais je préfère laisser aux artistes de plus en plus de contrôle sur le résultat. Ceci dit, je leur procure toujours les ressources nécessaires, à eux ensuite de choisir le degré d’implication curatoriale de ma part dont ils ont envie, s’ils souhaitent l’aide de techniciens, s’ils veulent engager quelqu’un pour écrire un texte… C’est ma manière de faire mais quiconque utilise Curatron peut choisir d’avoir plus d’impact curatorial sur le groupe, tant qu’il le précise dans l’appel à projets. L’usage de Curatron ouvre une infinité de scénarios.
Qu’est ce qui vous a inspiré pour créer Curatron ?
Le temps passé dans l’Arctique canadien où j’ai vécu en 1999 a été le déclencheur de mes intérêts actuels qui ont mené au développement de Curatron. Lorsque j’ai approfondi mes connaissances sur le passage d’une société basée sur la chasse et la pêche à une société industrialisée qu’ont connu les Inuits relativement récemment, je me suis intéressé davantage à cette transition au cours de l’Histoire sur un plan plus général et plus mondial. L’avènement de l’agriculture a enclenché la sédentarité, la division du travail, modifié les conceptions de propriété publique et privée, mené à l’accumulation du capital, à la division des classes et au développement urbain. Les répercussions culturelles qui peuvent émerger d’une innovation si ancienne sont devenues un important centre d’intérêt pour moi : je me suis demandé s’il était possible de revenir à certaines structures sociales des sociétés de chasseurs-cueilleurs tout en maintenant une infrastructure technologique avancée.
Je me suis ensuite inscrit dans la section « art dans l’espace public » aux beaux-arts de Stockholm où j’ai étudié l’esthétique relationnelle, la propriété intellectuelle et la critique institutionnelle, entre autres, et ai concentré mes recherches sur des technologies destinées à atteindre cet équilibre techno-primitiviste. C’est alors que j’ai réalisé qu’Internet a certains principes en commun avec ces sociétés de chasseurs-cueilleurs. The Stone Age Electronic Calculator est l’un des projets fondateurs de ma pratique actuelle. C’est un site collaboratif (wiki) qui permet à une communauté de contributeurs de produire un manuel de fabrication d’une calculatrice sans outils, constructible dans les bois. Il s’agit d’une réflexion sur la possibilité de créer un système de production technologique qui permette la propriété publique sur l’ensemble de l’infrastructure de calcul tout en maintenant un style de vie de chasseurs-cueilleurs.
Après mon diplôme, j’ai cofondé Platform Stockholm, un collectif d’ateliers qui regroupe cent-dix artistes. J’ai alors commencé à créer des systèmes informatiques de production participative pour externaliser les décisions administratives à l’ensemble des artistes. Par exemple, nous avons un système de vote mensuel de répartition d’une partie du budget. Un an plus tard, je suis parti vivre en Norvège travailler pour une société informatique et j’ai commencé à gérer Platform à distance. J’ai appris à développer des systèmes plus sophistiqués et, lorsqu’un espace pour une galerie s’est libéré dans le bâtiment qui abrite Platform, les choses m’ont apparu évidentes. J’ai essayé de donner le contrôle sur la première exposition au collectif d’artistes, les artistes présents dans le bâtiment votaient donc pour choisir les artistes exposés, mais j’ai réalisé qu’il serait sans doute plus intéressant que les artistes qui souhaitaient exposer votent entre eux. C’est ainsi qu’est né Curatron.
Lorsque vous décrivez le processus de sélection, vous dites que Curatron est « plus complexe qu’un simple système de vote » et qu’il « “décide” du groupe d’artistes qui exposera en fonction de motifs de connection entre les artistes qui émergent lors du stade d’évaluation entre pairs. En d’autres termes, si un artiste est sélectionné par l’ensemble de ses pairs, cela ne garantit pas qu’il participe à l’exposition. Le logiciel teste plutôt quelque chose du ressort d’un goût collectif en reconnaissant les groupes qui apparaissent dans différentes propositions de sélections ».
Pouvez-vous, tout d’abord, m’en dire plus sur ces « motifs de connection », comment les caractériseriez-vous et comment les avez-vous choisis ?
Ensuite, j’aimerais que vous expliquiez le rôle que cette notion de « goût collectif » peut avoir dans la production d’une exposition et dans quelle mesure Curatron peut aussi être envisagé comme un outil hautement critique quant aux stratégies de profilage et de micro-ciblage qui sont désormais utilisées de manière très générale dans le secteur commercial mais aussi en politique1.
Les motifs de connection proviennent de la manière dont on valorise les sélections qui sont opérées entre les gens, un principe basé sur une logique simple permettant d’établir un « choix collectif ». Non que j’aie réussi à développer une forme pure de « choix collectif » mais l’idée de mettre au point un tel choix est celle qui motive réellement ce projet.
Voici une décomposition du processus :
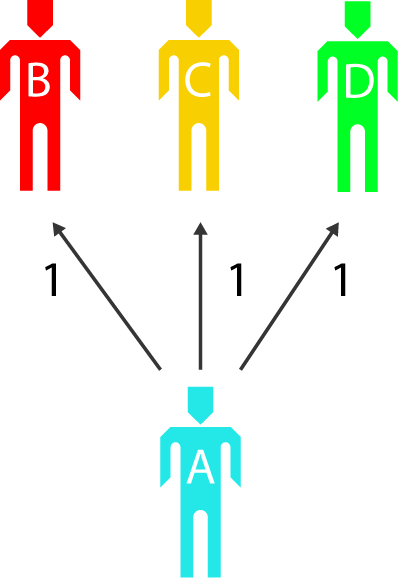
- La sélection personnelle
Lorsqu’une personne choisit une autre personne, une valeur est créée entre elles.
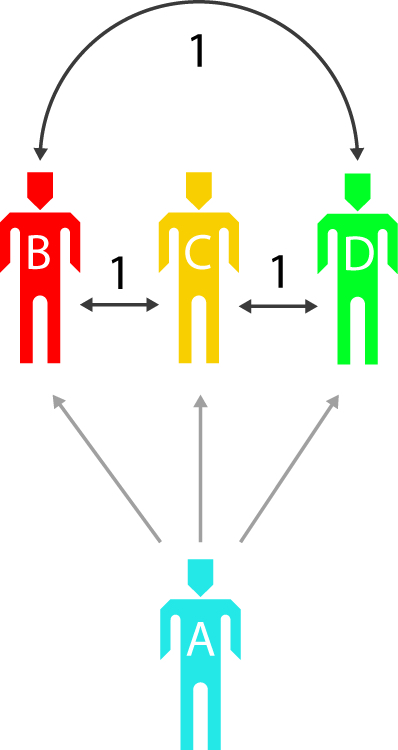
- La sélection de groupe
Lorsque chaque personne choisit plusieurs autres personnes, elles créent de la valeur entre elles et ces autres personnes mais elles créent aussi de la valeur entre ces autres personnes, indépendamment d’elles-mêmes.
Les valeurs de la sélection personnelle et de la sélection de groupe sont évaluées différemment. Pour l’instant, vous créez plus de valeur entre les personnes en les sélectionnant pour faire partie d’un groupe que vous n’en créez en choisissant de vous associer avec elles. Ces valeurs étaient auparavant considérées comme équivalentes, mais nous avons découvert au fil du temps que la manière dont un utilisateur pense sa pratique en regard d’une autre est moins juste que sa perception des autres pratiques les unes par rapport aux autres.
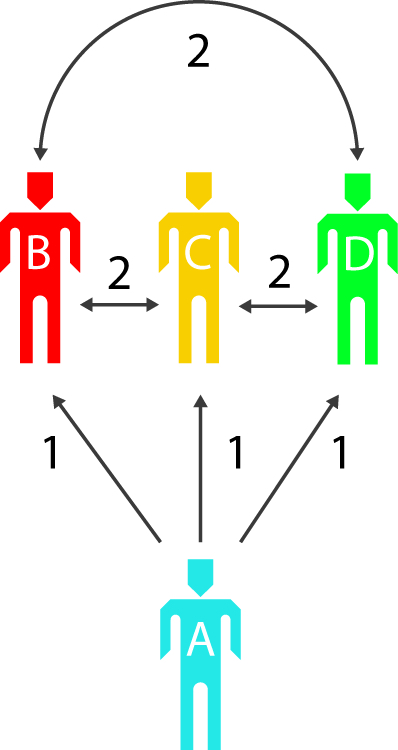
Une fois que tous les participants ont créé des groupes (produisant ainsi de la valeur entre les pratiques), on lance un algorithme basique qui compile toutes les valeurs et produit un groupe final à partir d’elles.
Considérons par exemple un appel à candidatures pour une exposition de cinq artistes, soit quatre artistes plus notre sujet. L’on explique aux candidats que la meilleure manière d’optimiser leur sélection est de choisir des artistes avec la pratique desquels ils sentent des affinités. Cette perception des similiarités permet plus de recoupements entre les choix des participants, comme le montrent les diagrammes.
On calcule ensuite toutes les combinaisons de cinq possibles à partir de l’ensemble des participants : le groupe qui a la valeur la plus élevée est le groupe final. Ce nombre s’appelle la cohésion de groupe. Il ne se base pas sur les artistes les plus populaires mais sur le groupe le plus populaire dans lequel les relations entre les pratiques ont été perçues comme les plus importantes par les participants. Nous essayons de former le groupe qui définit une tendance significative parmi l’ensemble des participants.
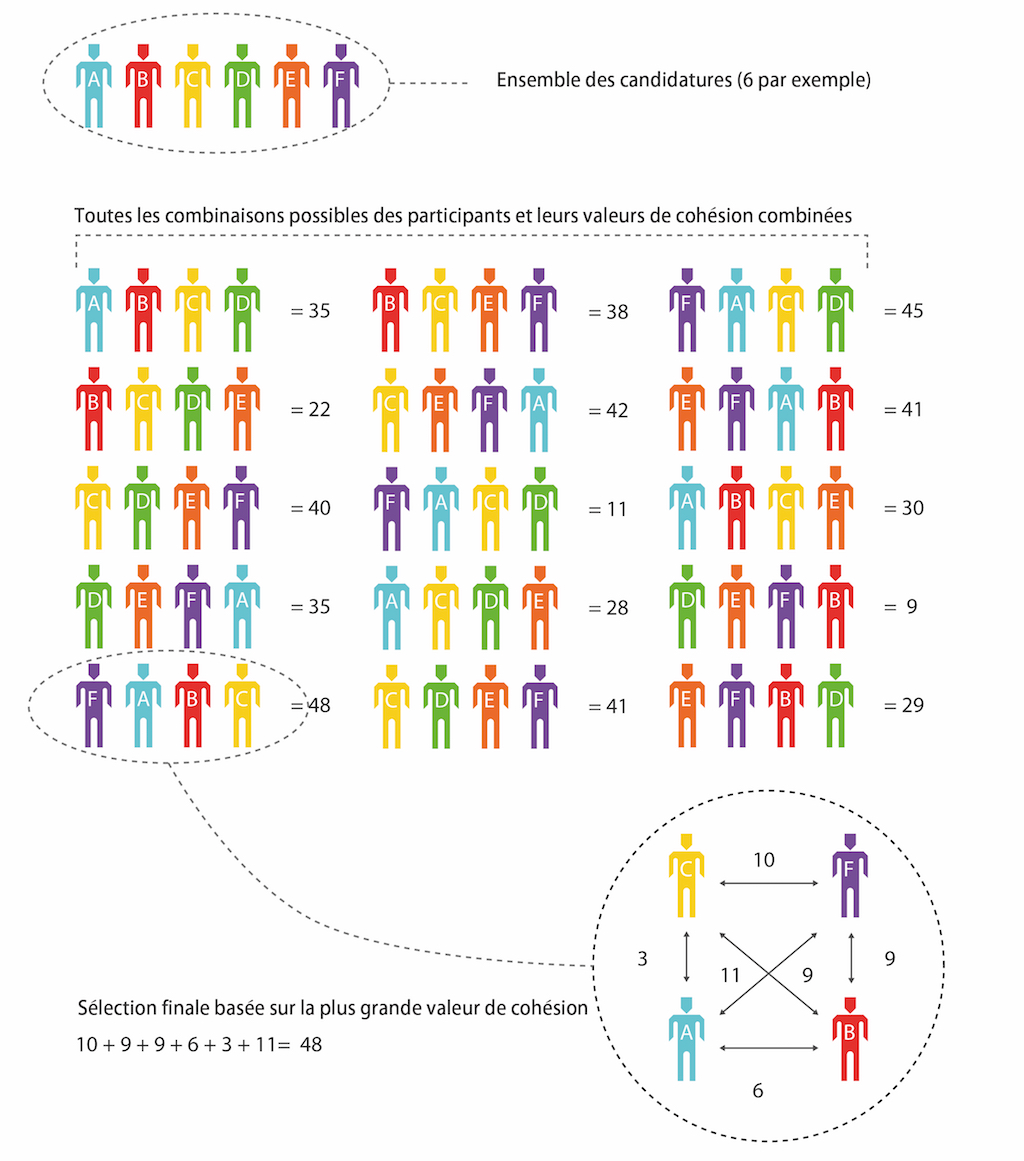
Curatron procure une méthodologie alternative à l’appel à candidatures traditionnel tout en pouvant être considéré comme un type d’appel à candidatures. Au lieu que l’examen des candidatures soit réalisé par une seule personne ou par un groupe de décideurs, il est opéré par les candidats eux-mêmes, ce qui requiert un processus tout différent : nous devons rendre les dossiers de candidatures visibles, ce qui crée de nouvelles possibilités d’interactions sociales. Ces interactions ont lieu entre les participants, les sélectionnés, l’équipe du lieu d’exposition, les visiteurs de l’exposition (physiques et virtuels), les développeurs du logiciel, les subventionneurs et moi-même.
La recherche du goût collectif ne fonctionne donc pas simplement comme un contexte pour mettre en place l’exposition mais permet à des formes d’interactions sociales d’advenir hors du seul groupe d’artistes sélectionnés. Au final, une exposition créée avec Curatron peut ne pas sembler différente d’une exposition mise en place par des moyens plus standards, mais son processus aura impliqué de nouvelles méthodes de travail : les artistes étant sélectionnés de manière totalement différente, leur relation au curateur s’en trouve évidemment affectée, permettant d’envisager des structures de travail inhabituelles.
La plupart de mes pièces précédentes explorent les zones controversées des tendances technologiques émergentes, principalement en lien avec les idéaux émancipateurs de la propriété collective dans le cadre d’une infrastructure technologique partagée. Les défis qui entourent la production en open source, les processus d’échanges en ligne, les questions de données publiques et privées et l’automatisation forment mon histoire et mes intérêts actuels. J’explore les obstacles possibles ou les opportunités sur la voie d’une utopie de production participative relevant de la propriété collective et mon travail ne cherche pas à être ouvertement critique mais il peut en effet être lu de cette manière. Cependant, il m’est assez difficile d’établir un lien entre Curatron et le micro-ciblage. Tous deux utilisent des analytiques sociales et la reconnaissance de motifs pour produire leur résultat, mais…
Je pensais plutôt au fait qu’essayer de définir un « goût collectif » pouvait être une opposition affirmée au micro-ciblage et à la manière dont fonctionne la majeure partie du web aujourd’hui, cherchant à produire une expérience « personnalisée » pour l’utilisateur/consommateur/cible.
La manière dont Curatron fonctionne maintenant se base sur une définition du goût collectif à laquelle tout le monde ne souscrit pas forcément, à savoir celle de déterminer le groupe le plus populaire parmi l’ensemble des participants. La logique que nous suivons pour cela peut être contestée mais cette définition me semble personnellement la meilleure. La manière dont nous définissons le goût collectif est intégrée à l’algorithme que nous utilisons (sélection, cohésion, etc.) : la sélection personnelle, par exemple, représente la valeur entre le sélectionneur et le sélectionné, la perception de sa propre pratique par rapport à celle des autres ; la cohésion de groupe représente la valeur entre le sélectionneur et ceux qu’il a sélectionnés, soit sa perception des autres pratiques les unes par rapport aux autres. Lorsque nous calculons le groupe final, nous amalgamons des goûts individuels en une décision de groupe et valorisons certaines définitions du goût par rapport à d’autres. Cet algorithme pourrait prendre d’autres formes, chacune étant une définition hypothétique de ce que peut être le goût collectif.
Le goût collectif tel que je l’envisage peut avoir toutes sortes d’usages, il pourrait être utilisé comme une forme de stratégie d’opposition pour organiser les fils d’information des gens et dissiper les fausses informations en provenance des sollicitations non désirées. Pas dans sa version actuelle, cependant, bien que ce ne soit pas nécessaire pour le considérer comme critique du micro-ciblage.
Qu’est ce qui est donc en jeu derrière votre manière de penser le goût collectif ?
Le goût collectif est pour l’instant un idéal que je cherche à obtenir avec Curatron, mais qui est peut-être impossible. Curatron n’en est encore qu’à ses balbutiements, c’est une manière relativement rudimentaire de mesurer les goûts d’un certain nombre de personnes. Il ne présente qu’une idée singulière de ce qu’est le goût collectif basée sur la manière dont je pense que l’algorithme peut le refléter et avec les moyens qui sont les miens. Cependant, il propose une véritable stratégie de travail pour une intelligence collective appuyée sur une structure informatique dans une communauté artistique indéterminée. Pendant ces trois premières années, j’ai tenté de plusieurs manières de me retirer du projet en tant qu’auteur, en externalisant certaines taches liées à son développement, mais la prochaine étape sera une tentative de m’en retirer de manière programmatique. M’en retirer entièrement et permettre ainsi un contrôle collectif total de son développement est mon but ultime pour Curatron. L’intelligence collective dans ce contexte est autant une culture que le système informatique qui la soutient.
Considérez-vous Curatron comme l’une de vos œuvres ou plutôt comme un projet curatorial, ou un peu des deux, ou bien n’avez-vous aucune envie de le catégoriser ?
Comme les deux à la fois mais le définir n’est pas l’une de mes priorités. Il fait vraiment partie de ma pratique et je me décris en général comme un artiste lorsqu’on me demande quelle est ma profession. Le curating fait partie intégrante de ma pratique et je dirige mon propre lieu d’exposition mais tout cela a découlé de ma pratique artistique. Je m’attèle aux mêmes questions dans ces autres champs que lorsque je produis de l’art mais je pense que Curatron peut être considéré comme une œuvre d’art, ou comme une œuvre employant des stratégies curatoriales. Cependant, je ne souhaite pas que ma définition de l’art limite la compréhension que les autres peuvent avoir de Curatron.
Y a-t-il des projets relativement similaires dont vous pouvez vous sentir proche ?
Eh bien, il y avait un groupe d’artistes à Oslo, Tidens Krav, qui utilisait des procédés d’appels à projets plutôt non conventionnels, comme lorsqu’il demandait aux candidats de postuler via un message laissé sur son répondeur.
Et puis vous connaissez l’algorithme de Jonas Lund qui lui donnait des instructions pour organiser ses expositions relativement aux galeries qui l’invitaient, mais Jonas travaille à pirater les infrastructures d’une manière différente de la mienne. Ces deux références valent pour le contexte artistique, mais dans celui de l’informatique, ce qui se rapprocherait le plus de Curatron serait Tinder 1.0, qui était une version très simple qui permettait de placer des valeurs entre les utilisateurs et non sur eux.
1 Voir par exemple la présentation d’Alexander Nix, P-DG de Cambridge Analytica lors du Concordia Summit en septembre 2016 intitulée « The Power of Big Data and Psychographics », lors de laquelle il s’exclame que ses enfants ne comprendront certainement jamais ce que pouvait être la communication de masse. Cambridge Analytica élabore des stratégies de communication électorales basées sur la prospection et l’analyse de données, elle a d’abord travaillé pour Ted Cruz en 2015 puis pour Donald Trump en 2016. L’entreprise britannique a aussi pris part à la campagne pro-Brexit et aurait été approchée par Marine Le Pen.
https://www.youtube.com/watch?v=n8Dd5aVXLCc (Merci à Hannes Grasseger d’avoir diffusé cette vidéo lors du symposium Bot Like Me au centre culturel suisse de Paris, le 3 décembre 2016.)
Entretien avec Jeremy Bailey

Si « une grande partie des données stockées dans le cloud sont nos propres données, les photos et contenus divers uploadés depuis nos disques durs et nos téléphones » à l’heure où le contenu généré par les utilisateurs domine le contenu disponible en ligne et que « le cloud est, de toute évidence, notre cloud (c’est la promesse du “je” qu’est le “I” de l’“iCloud” d’Apple, ou, pour faire référence à des temps plus anciens, du “mon” qu’est le “my” de “mySpace”)1 », elles sont bien évidemment néanmoins contrôlées par les modérateurs, humains ou algorithmiques, des plateformes et des sites sur lesquels nous les transférons. Jusqu’ici rien de bien étonnant, il en est absolument de même dans l’espace public lui même régi par des lois (comme l’interdiction de se promener nu dans la rue, tout au moins dans en France). Cependant ces contrôles vont bien au-delà d’une simple vérification de contenus dans la limite de tout ce qui ne nuit pas à autrui, d’autant plus qu’ils ne sont majoritairement pas produits par les instances étatiques démocratiques — et il y aurait déjà là de quoi ouvrir le débat — mais par les mêmes sociétés privées qui détiennent donc ces espaces « d’expression », sur des bases plus qu’opaques2.
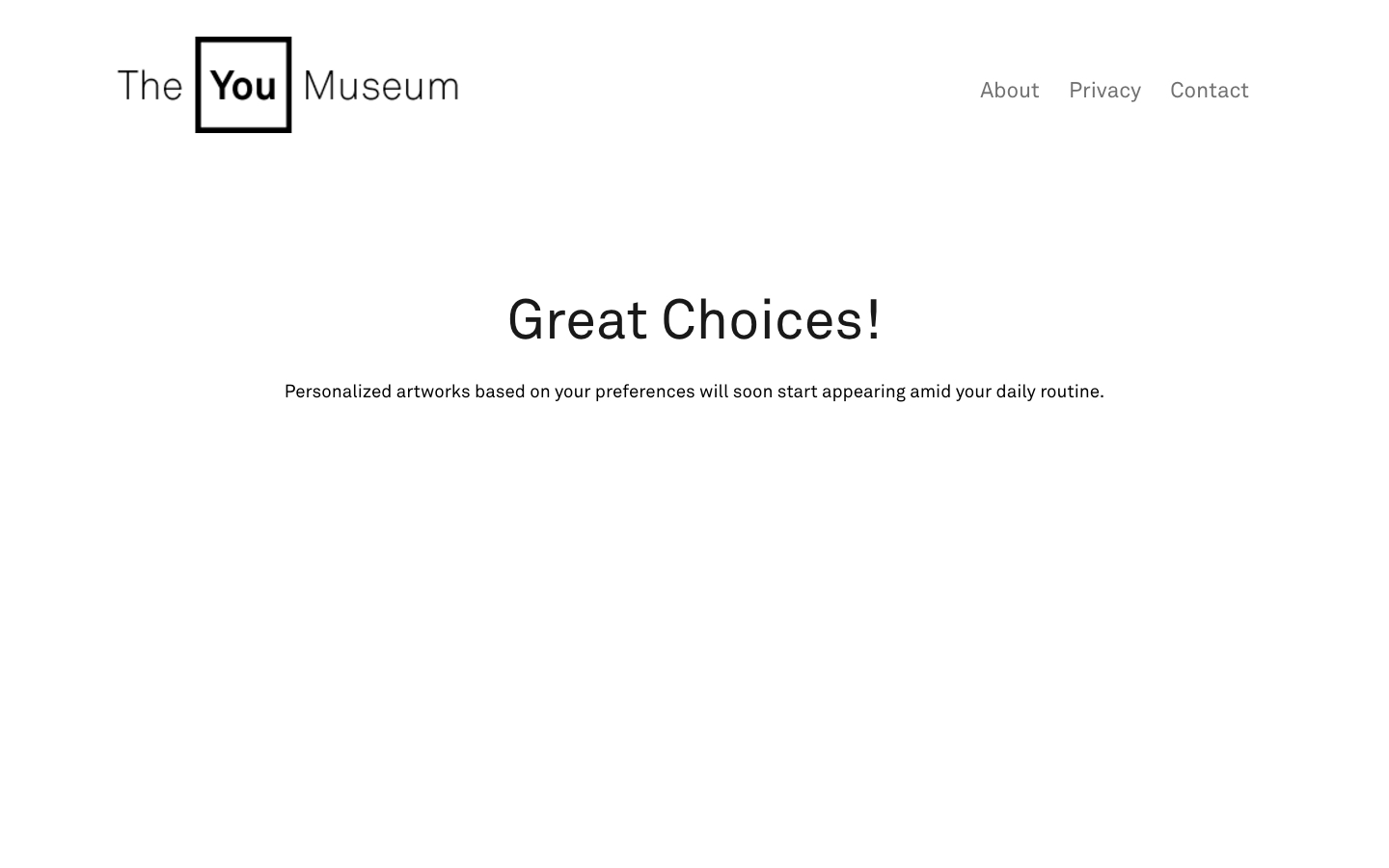
C’est cette promesse du « je » que nous mettons en discussion ici avec celui qui nous a habitués à assener des vérités sous des atours drôlissimes, que ce soit lorsqu’il se rebelle contre la toute-puissance des curateurs dans le monde de l’art (que l’on ne manquera pas de comparer, ne serait-ce que de loin, au content curators qui sévissent sur Internet) : « les curateurs, ils rassemblent les meilleurs trucs sur lesquels d’autres personnes ont travaillé dur dans un même espace et en reçoivent tout le crédit » (Nail Art Museum, 2014) ou contre l’ultra-narcissisme généré par le web 2.0 : « bientôt, nous porterons nos données comme vêtements » (The Web I Want, 2015). Nous revenons donc avec Jeremy Bailey sur son projet phare, le You Museum, qui se présente comme « une plateforme qui délivre des expositions personnalisées dans les espaces publicitaires qui utilisent la technologie du remarketing », soit ces espaces dans lesquels se glissent des publicités pour des sites que nous venons tout juste de visiter. Le ciblage du goût des « visiteurs » du musée se fait selon un questionnaire très simple concernant leur personnalité (enjouée et énergique ou réservée et mesurée), le type de formes (organiques et courbes ou géométriques et pointues) et d’objets qu’ils préfèrent (petits et discrets ou grands et imposants) et il leur est ensuite possible, en cliquant sur l’encart présentant une œuvre qui leur plaît, d’en acheter le « souvenir » imprimé sur un sac, un mug ou un coussin. Exactement comme dans un musée irl.
The You Museum fonctionne depuis maintenant deux ans. Comment se porte-t-il ?
Si vous deviez comparer son activité à celle d’une « marque » plus classique, de quel type de marque se rapprocherait-il en matière d’audience ?
Très bien ! Il a reçu pas loin de 40 000 visiteurs, presque 4 000 personnes s’y sont déjà inscrites et il a déjà diffusé plus de 10 millions de bandeaux publicitaires. Le flux d’activité s’est légèrement ralenti mais un nombre stable de personnes l’expérimentent néanmoins chaque mois. Au total, j’ai dépensé environ $8 000 pour ce projet et je continue de l’alimenter grâce aux retours positifs des nouveaux venus.
Beaucoup de marques utilisent la même technologie que le You Museum mais aucune n’est réellement autoréflexive à ce sujet et à sa manière. J’imagine que si on devait le comparer à une marque, celle-ci devrait être particulièrement consciente d’elle-même et autocritique. Patagonia, peut-être, avec ses super publicités qui préconisent de ne pas acheter ses produits. Ceci dit, la portée de mon audience est évidemment très faible comparée à celle des grandes marques mais elle est très importante comparée à celle de la plupart des marques personnelles. L’un des aspects importants de ce projet et de mon travail en général est de réfléchir à ce que signifie désormais une identité à l’ère d’Internet. Aujourd’hui, chacun est censé se promouvoir lui-même en ligne. On ne cesse d’entendre que les marques ressemblent de plus en plus à des personnes et que les gens agissent de plus en plus comme des marques, mais l’on est rarement confronté à cette idée sous une forme aussi extrême que celle mise en œuvre avec The You Museum.
En parlant de portée d’audience, comment nommez-vous celle du You Museum ? Ces gens sont-ils vos abonnés, vos clients, vos cibles ?
En tant qu’artiste-performeur, je les considère avant tout comme un public. Je pense aussi en termes d’utilisateurs dans le domaine du logiciel entendu comme service. Ma cible est très large mais elle est relativement restreinte à ceux qui sont dans un rapport critique avec le monde qui les entoure, ceux qui aimeraient voir l’art traiter son sujet en contexte et non depuis un white cube stérile.
Sur un plan conceptuel, le produit est le public car il prend conscience de la manière dont il est suivi à la trace et de la cible marketing qu’il est sur Internet. Internet a été pensé comme un espace public de partage des connaissances mais il est devenu un centre commercial. Cette œuvre existe donc en chaque utilisateur, c’est lorsqu’ils accomplissent l’acte de naviguer sur Internet qu’elle se crée.
Il s’agit donc d’une œuvre en forme de stratégie commerciale. Les objets en vente parodient ceux que l’on trouve dans les boutiques des musées (mugs, coussins, sacs en toile…) puisqu’aujourd’hui, la plupart des grands musées sont devenus des marques, produisant des objets promotionnels et des gadgets souvenirs pour asseoir leur identité et soutenir leur économie. Votre réplique de ce schème est-elle aussi une manière d’aborder la question de la financiarisation du marché de l’art ?

Sous son aspect inoffensif car ouvertement humoristique, le You Museum a donc recours, tout comme les entreprises du secteur de la publicité et de la communication, à des méthodes statistiques pour classifier ses cibles selon leur soi-disant goûts, méthodes dont il se moque en posant trois questions ironiques (à la fois très ouvertes et très limitatives) à ses futures cibles. 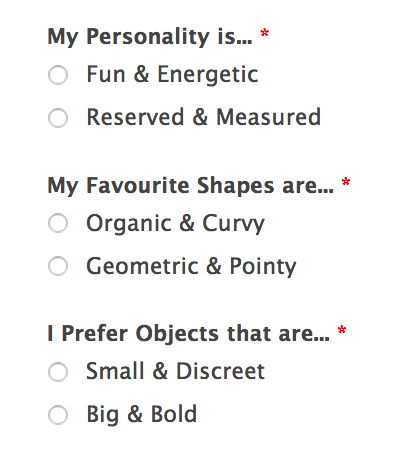
Oui, il est triste que l’ancien web ait disparu il y a longtemps, même la plupart des sites personnels sont maintenant réalisés à partir de templates. L’utopie de l’information comme bien commun est un lointain souvenir, excepté peut-être à certains endroits, comme wikipédia, par exemple — bien que je ne pense pas que tout cela ne soit que de l’histoire ancienne. J’ai conçu le You Museum à Istanbul où je suis arrivé juste après les soulèvements du parc Gezi. Ces manifestations avaient commencé alors que le gouvernement s’apprêtait à attribuer l’un des rares parcs du centre-ville à un promoteur qui comptait en faire un centre commercial et un immeuble dans le style ottoman de la caserne qui s’élevait auparavant sur le site. Le fait qu’un parc, un lieu public créé pour la communauté, l’un des seuls espaces de ce type dans la ville soit transformé en un centre commercial et en des appartements pour les plus aisés s’appropriant le style d’un symbole militaire de l’ancien empire… Eh bien, Internet est victime du même type de pressions. MAIS le parc Gezi n’est pas devenu un immeuble et une aire de jeux y a même été installée pour les enfants. Le même type de protestation va advenir sur Internet et cela permettra de créer une belle communauté. Il y a déjà un nombre incroyable de gens qui utilisent des bloqueurs de publicité, 25% des utilisateurs d’Internet la dernière fois que je me suis renseigné à ce sujet.
Oui, je crois vraiment que tant que nous nous attacherons à détourner la technologie, elle n’aura que peu de pouvoir sur nous. Transformez votre micro-onde en piano, votre ordinateur en four, ou simplement changez de genre sur Facebook et vous commencerez à voir apparaître des publicités pour le déodorant Axe.

2 http://international.sueddeutsche.de/post/154513473995/inside-facebook
- Publié dans le numéro : 80
- Partage : ,
- Du même auteur : Paolo Cirio, RYBN, Sylvain Darrifourcq, Computer Grrrls, L’histoire polyphonique du Net Art, un Eternal Network?,
articles liés
Du blanc sur la carte
par Guillaume Gesvret
Claire Staebler
par Patrice Joly
Arnaud Dezoteux
par Clémence Agnez

