Kate Crawford | Trevor Paglen

Les images à l’œuvre
La situation est la suivante : nous nous trouvons dans un espace nommé Osservatorio (qui n’est pas un ancien observatoire) et nous regardons des images qui ne sont pas destinées à être regardées comme de l’art mais qui sont exposées comme tel bien qu’elles ne prétendent pas en être et que les artistes / auteurs de l’exposition ne le prétendent pas non plus. La plupart de ces photos sont des portraits, à l’exception de quelques documents historiques.
La première série de visages qui nous est donnée à voir a été extraite de l’ensemble de données FERET, une collection de 14 126 images de visages de 1 199 personnes recueillies entre 1993 et 1996. Le programme FERET — acronyme de Face Recognition Technology — était un programme de recherche du ministère américain de la Défense visant à développer « des capacités de reconnaissance automatique des visages qui pourraient être utilisées pour assister le personnel de sécurité, de renseignement et des forces de l’ordre dans l’exercice de leurs fonctions1». Il a donné naissance à la première « grande » base de données créée dans le but d’améliorer les techniques de reconnaissance faciale d’une manière générale, contrairement aux ensembles de données habituellement créés par des développeurs pour entraîner et tester les algorithmes particuliers qu’ils programmaient. Pour le National Institute of Standards and Technology, « avant le début du programme FERET, il n’y avait aucun moyen d’évaluer ou de comparer avec précision les algorithmes de reconnaissance faciale2. » La question de l’objectivité des algorithmes de reconnaissance faciale est précisément l’enjeu de cette exposition proposée par Kate Crawford, professeure et chercheuse en intelligence artificielle, et Trevor Paglen, artiste et chercheur.

Le deuxième ensemble de données que l’on rencontre aborde la question plus frontalement : il s’agit de photos de personnes — désormais décédées — arrêtées à plusieurs reprises qui permettent de suivre l’évolution de leur apparence en incluant des facteurs comme la pousse des cheveux ou le vieillissement. Le MEDS-II (pour Multiple Encounters Dataset-II) a été créé en 2011 à partir d’images et de métadonnées fournies par le FBI, c’est-à-dire d’images qui n’ont pas été produites à dessein mais qui ont été recyclées ou upcyclées, c’est selon. Comme ces photos ont elles aussi été collectées aux États-Unis, on y voit principalement des hommes blancs ou noirs, très peu de femmes et encore moins de personnes asiatiques. Comme les réseaux sociaux et les sites d’hébergement d’images en étaient encore à leurs balbutiements (Facebook et Flickr n’avaient que cinq ans lorsque les premiers fichiers MEDS ont été mis en place), où était-il alors possible de se procurer des photos de personnes sur une période de temps significative et avec les données d’identité correspondantes ? Il y avait principalement deux viviers : les célébrités et les condamnés.
Il a peut-être été plus facile pour le gouvernement d’opter pour la deuxième solution car la base de données était en quelque sorte déjà existante et vérifiée. Ce qui ne veut pas dire qu’elle était représentative. Trevor Paglen le souligne avec humour : « Ces deux ensembles de données sont gérés par l’Institut national des normes des États-Unis, ils sont à la reconnaissance faciale ce que le kilogramme est au poids3 ! »
La création de normes pour les machines est évidemment un aspect crucial. Alors comment peut-on réduire ce processus à des données recueillies auprès de quelques centaines de personnes travaillant dans une université ou dans l’armée et acceptant de donner leur image pour faire avancer la recherche ?
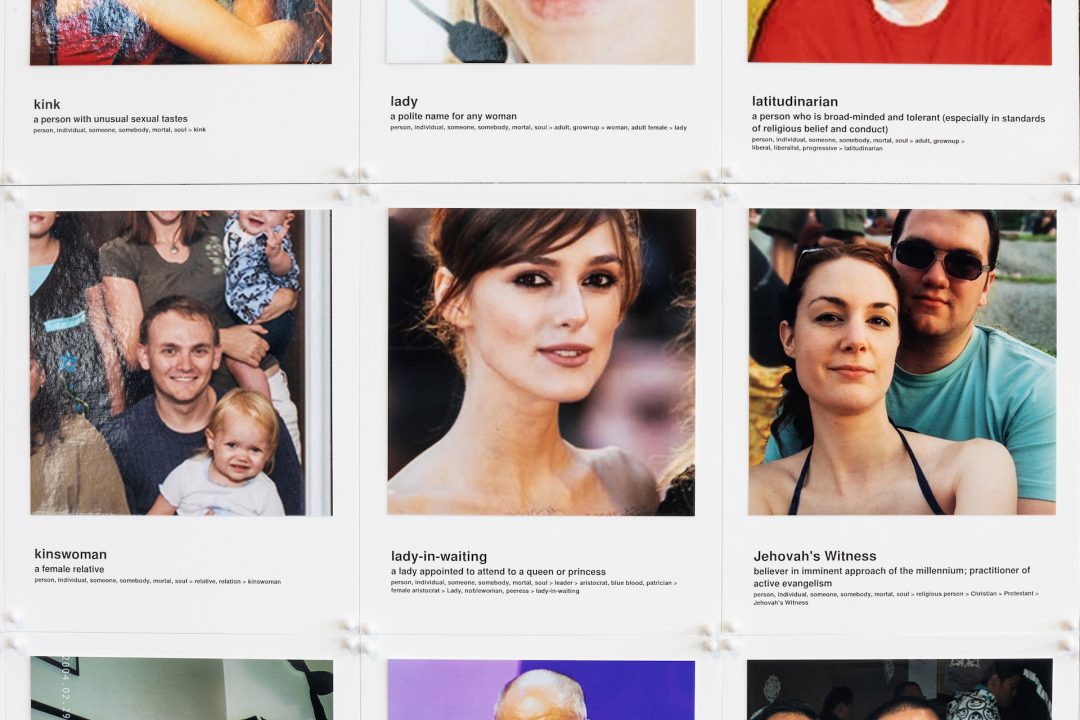
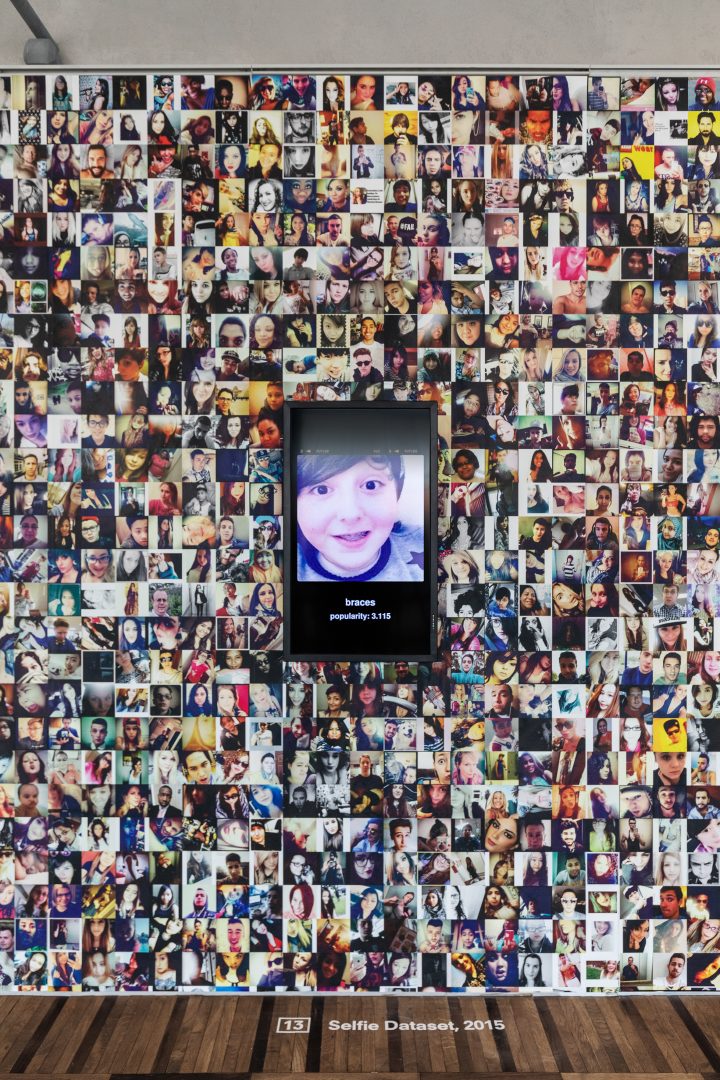
L’option des célébrités avait elle aussi été choisie par quatre chercheurs qui, en 2007, ont publié un ensemble de données intitulé Labeled Faces in the Wild, une collection de 13 233 images de 5 749 célébrités « recouvrant l’ensemble des conditions habituellement rencontrées dans la vie quotidienne » par opposition à « la plupart des bases de données de visages [qui] ont été créées dans des conditions contrôlées pour faciliter l’étude de paramètres spécifiques de la reconnaissance faciale4.» Crawford et Paglen en exposent les images aux côtés de celles du Selfie dataset qui, comme son nom l’indique, est un ensemble de selfies. Mais ces 46 836 selfies ont-ils eux aussi été donnés pour faire avancer la recherche ? Eh bien, non. Ils ont été tout bonnement récupérés sur Instagram par le centre de recherche en vision assistée par ordinateur de l’université de Floride centrale.
L’année 2015 a en effet été marquée par la mise à disposition de deux ensembles de photos d’« anonymes » vivants recueillies sans leur consentement : Selfie et Brainwash, ce dernier étant composé d’images extraites d’une webcam située dans un café de San Francisco. Bien que Brainwash, produit par l’université de Stanford, ait été retiré de son site internet officiel en juin 2019 après qu’il ait été divulgué par les artistes et chercheurs Adam Harvey et Jules Laplace5 qu’il était notamment utilisé par l’université nationale de technologie de défense chinoise et par des chercheurs affiliés à Megvii, une société chinoise leader en matière d’IA qui fournit des logiciels de reconnaissance faciale entre autres à Lenovo et Huawei, Selfie est, lui, toujours disponible. Il est à noter que nous ne mentionnons ici que les ensembles de données de recherche accessibles au public mais, bien entendu, il en existe des dizaines de privés dont nous ignorons plus ou moins l’existence, comme ceux qui sont utilisés en interne chez Google ou Facebook, par exemple.
N’oublions pas que « Facebook possède la plus grande collection de visages humains de toute l’histoire », indique Kate Crawford, « une archive privée de tant de visages humains qu’elle est sans nul doute comparable aux gigantesques collections des plus puissantes familles de l’histoire européenne : ce sont les Médicis des visages ! » ajoute-t-elle avec à-propos — nous sommes à Milan.
Présenter de telles images dans un espace d’exposition dédié à l’art soulève bien sûr des questions classiques du monde de l’art telles que : quelle est la différence entre regarder une photographie dont nous savons qu’elle est de l’art et regarder un selfie d’une personne que nous ne connaissons pas sur un réseau social ?
Mais la situation soulève des questions plus urgentes car ce que nous regardons ici, ce sont des images qui sont principalement regardées par des systèmes de vision artificielle, des images qui peuvent avoir été produites par des humains pour des humains mais qui finissent par être utilisées par des machines pour regarder les humains.
Il y a quelques années, dans un essai très pertinent, Trevor Paglen nous prévenait déjà que : « La culture visuelle humaine est devenue un cas particulier de la vision, une exception à la règle. L’écrasante majorité des images est désormais fabriquée par des machines pour d’autres machines, les humains étant rarement dans la boucle7. » Cela signifierait-il que les images deviennent de plus en plus opératoires ? Le but des images ainsi nommées par Harun Farocki8 à l’aube du millénaire n’est pas la représentation mais l’action, la participation active aux affaires humaines. Cette idée n’était alors pas vraiment nouvelle, en fait, elle a même déjà une soixantaine d’années. Il y a maintenant soixante ans que les images ont commencé à nous échapper.
À l’origine de cette révolution, parmi quelques autres avancées scientifiques et technologiques significatives dans le domaine, se trouve notamment une étude des neurobiologistes David H. Hubel et Torsten Wiesel, publiée en 1959, sur le traitement de l’information par les neurones du cortex visuel chez le chat9. Leur découverte de l’impact de l’environnement visuel sur la structuration de la vision et de son fonctionnement par analyse de couches d’information, combinée aux résultats des recherches de neurologues sur les réseaux neuronaux des grenouilles10, également dévoilés en 1959, formera la base de ce que l’on appelle l’apprentissage approfondi (ou plus communément deep learning) en intelligence artificielle. Les algorithmes d’apprentissage approfondi, présents dans la majorité des réseaux neuronaux artificiels (eux aussi réellement mis en application en 1959)11, sont utilisés dans de nombreux domaines, de la traduction automatique aux assistants personnels en passant par le trading, pour n’en citer que quelques-uns, mais nous nous concentrerons ici sur la vision artificielle. Tout comme le fonctionnement des réseaux de neurones artificiels est basé sur celui (supposé) des neurones naturels, la vision par ordinateur s’inspire du raffinage de l’information visuelle dans le cortex humain12 et animal13. À cette fin, l’image qui est entrée dans le système, comme l’image perçue, est décomposée en différents éléments : en résumé, formes, reliefs et couleurs. Bien entendu, pour être compréhensible par la machine, elle est traduite en séquences de chiffres, d’équations et d’autres fonctions, un procédé mis au point en 1957 par l’ingénieur Russell A. Kirsch, créateur du scanner numérique et, donc, de la première image numérique. « Que se passerait-il si les ordinateurs pouvaient voir le monde tel que nous le voyons14 ?» C’est pour répondre à cette question qu’il entreprit de diviser la désormais célèbre photo de son fils en petits carrés aux propriétés descriptibles mathématiquement : les pixels.
À la même époque, un mathématicien et informaticien travaillant sur la lecture automatique et, plus particulièrement, sur la reconnaissance de caractères, se faisait ambitieux ; à propos de ces années de recherche et des rêves qu’il avait alors, Woodroe W. Bledsoe a écrit : « Je voulais qu’il lise les caractères imprimés sur une page et l’écriture manuscrite également. Je pouvais voir celà, au moins en partie, dans un petit appareil photo qui tenait sur mes lunettes, auquel était attaché uen oreillette qui me murmurait les noms de mes amis et connaissances que je rencontrais dans la rue… Car, voyez-vous, mon ami ordinateur avait la capacité de reconnaître les visages15. » Ainsi, en 1960, avec deux de ses collègues du laboratoire national de recherche et développement sur la sécurité nucléaire où il travaillait, il a créé Panoramic Research à Palo Alto — juste au début de la révolution du silicon16, bien avant que la vallée en prenne le nom—, une société dédiée à la recherche spéculative en intelligence artificielle et en robotique, pour en résumer les activités. Trois ans plus tard, Bledsoe publiait « un rapport sur un projet de reconnaissance faciale », qui est encore aujourd’hui la première tentative connue de conception « d’une solution à un problème de reconnaissance faciale simplifié17 ». Outre sa description d’un moyen de transposer la méthode de reconnaissance de caractères créée par Bledsoe à des images de visages humains, ce document met également en évidence le travail humain nécessaire au fonctionnement du système : « On estime que pour une future machine de reconnaissance, une certaine quantité de travail humain peut être très rentable. Par exemple, lorsque l’on donne une image à identifier à la machine, on peut demander à son opérateur de donner le sexe de la personne (s’il est connu), sa race, etc. et de fournir des renseignements quant à sa taille et son poids18. »
Ce projet de reconnaissance faciale ainsi qu’une grande partie des travaux menés par Panoramic Research ont été financés par le groupe King-Hurley, présumée société écran de la CIA19, ce qui exlique sans doute pourquoi si peu d’articles de Bledsoe ont été publiés jusqu’à présent20. L’un d’eux, le « rapport sur un projet de reconnaissance faciale » susmentionné, ouvre « Training Humans », l’exposition Paglen-Crawford à l’Osservatorio, ce qui a fait dire à Trevor Paglen, d’un ton acerbe : « Quand on se penche sur les fondements de la recherche sur l’intelligence artificielle et la vision par ordinateur, on trouve la CIA et quelques expériences très cruelles sur des chats21. » Il n’est donc pas si surprenant de lire le nom d’Alphonse Bertillon dans la bibliographie de ce rapport22 pas plus que, peut-être, de découvrir que Panoramic a apparemment aussi mené des recherches dans le cadre du tristement célèbre projet MK-Ultra, projet de recherche de la CIA notamment dédié au « contrôle de l’esprit et au lavage de cerveau » qui a conduit à la formalisation des techniques d’interrogation encore utilisées à ce jour23.
Si le mathématicien belge Adolphe Quételet a été le premier à appliquer les statistiques et les probabilités à la psychologie mais aussi à la criminologie, par le biais de mesures du visage et du corps humain entre autres techniques douteuses — il a d’ailleurs créé l’IMC — systématisant l’utilisation du corps dans le processus d’identification d’une personne, il a largement influencé Bertillon, le créateur français de l’anthropométrie judiciaire, un système de classification largement adopté par les services de police internationaux à partir des années 1890. Nous pouvons bien évidemment voir les informations biométriques intégrées dans les puces de nos passeports comme une version contemporaine du système Bertillon. La mesure de distances entre un œil et l’autre, entre le nez et la lèvre supérieure et l’application de ces données à l’identification des personnes n’ont pas seulement été utilisées au XIXe siècle pour condamner des récidivistes ou par Bledsoe pour apprendre à son ami ordinateur à reconnaître les visages, elles sont encore au cœur des systèmes actuels de reconnaissance des expressions faciales.
Non seulement les algorithmes de détection des émotions sont principalement utilisés « contre » les personnes qu’ils analysent — pour savoir si elles sont honnêtes dans leurs réponses lors d’un entretien d’embauche24 ou pour mieux les cibler en tant que client, parmi de nombreux autres exemples — mais ils sont fondamentalement défectueux. Prenons par exemple la base de données JAFFE (pour Japanese Female Facial Expression) qui compile 213 photos d’étudiantes en psychologie de l’université de Kyushu annotées de « l’expression prédominante […] que l’on a demandé au sujet de figurer », les six émotions exprimées étant : le bonheur, la tristesse, la surprise, la colère, le dégoût et la peur. Bien que cette base de données ait été publiée en 1998, les mêmes catégories et les cinq mêmes niveaux d’appréciation qui en sont proposés sont actuellement utilisés par les entreprises qui gardent l’humain dans la boucle pour la détection des émotions. La question étant : qu’est-ce qui permet de déduire l’état intérieur d’une personne à partir de son expression faciale ?
Baser un marché de plusieurs milliards de dollars sur « six émotions universelles » semble pour le moins absurde. Outre JAFFE, Crawford et Paglen ont choisi d’exposer les catégories de la base de données UTKFaces afin d’en souligner la « profonde simplification de la complexité humaine pour la rendre lisible par l’IA25 », pour reprendre les termes de Crawford. UTKFaces classe les personnes en deux sexes et cinq races : blanc, noir, asiatique, indien et autre. Pour continuer à citer Crawford : « Les systèmes d’IA réencodent ces types de compréhension étriquée de l’humanité ».

Mais la classification va plus loin, comme Paglen et elle le démontrent en décrivant le plus célèbre des ensembles de données présentés dans « Training Humans » — et probablement l’ensemble de données le plus célèbre tout court : ImageNet. L’idée derrière ce gigantesque ensemble de données créé en 2009 à l’université de Stanford était de « cataloguer intégralement le monde des objets, d’obtenir des images de chaque objet existant afin de pouvoir l’identifier : à ce jour, il y a 14,1 millions d’images classées en à peu près 20 000 catégories, la majorité étant des fruits, des animaux, des ustensiles… Et plus de 2 800 de ces catégories sont des catégories de personnes : hommes, femmes, trompettiste, débiteur — quelqu’un qui est endetté —, mais comment peut-on savoir ce qui se passe sur le compte bancaire de quelqu’un rien qu’en regardant son visage26 ? » demande Trevor Paglen.
Plus précisément, ImageNet est un ensemble d’images organisé selon la hiérarchie de WordNet, une base de données contenant la plupart des mots courants de la langue anglaise. Chaque concept significatif dans WordNet, si possible décrit par plusieurs mots ou expressions, est appelé synonym set ou synset. Il existe plus de 100 000 synsets dans WordNet, et le but d’ImageNet est de fournir en moyenne 1 000 images pour illustrer chacun. Pour ce faire, ImageNet compile une liste précise d’images web pour chacun d’entre eux. « Les images de chaque concept sont contrôlées en matière de qualité et annotées humainement27 » souligne son site web, en insistant, s’il était encore besoin de le faire, sur le fait qu’il n’existe pas de véritable intelligence artificielle mais seulement des systèmes homme-machine. Ce qui ne rend pas ces systèmes plus intelligents, il faut bien le dire. « Par exemple, à côté de catégories comme pom-pom girl, ou médecin, ou politicien, il y a aussi des catégories pour alcoolique, pour mauvaise personne, pour cleptomane, pour fasciste, pour menteur, pour perdant…Vous verrez des erreurs de langage, des erreurs de représentation, beaucoup de catégories qui sont parfaitement non visuelles. Il y a même une photo d’une personne décrite comme daltonienne. À quoi ressemble une personne daltonienne ? » interroge Kate Crawford. « Ce que vous voyez avec ImageNet est un exemple extrême de ce qui se passe dans tous les entraînements en général, à savoir qu’à un moment donné, la description d’une personne se transforme en un jugement sur elle28 » ajoute Paglen.
Se tenir devant une maison fait de vous un habitant, près d’un enfant fait de vous un être aimé, près d’un couteau fait de vous un meurtrier, près d’un téléphone fait de vous une call-girl. Tenir un micro fait de vous un annonceur, tenir un serpent fait de vous un charmeur. Tout cela est très littéral. Mais porter des lunettes et avoir l’air asiatique fait de vous un analyste. Vous avez demandé des clichés ? Kate Crawford, que j’ai déjà citée dans ces pages sur ce même sujet il y a quelques années29, s’est longtemps battue pour que les préjugés de l’IA soient reconnus mais, comme elle le rappelle, « quand je disais ça au début, c’était une hérésie30 ». C’est ce qui l’a amenée à co-créer l’AI Now Institute, « un espace interdisciplinaire pour que des sociologues, des anthropologues, des philosophes et des artistes — nous avons également invité Trevor à nous y rejoindre — puissent faire partie de cet institut qui produirait des études critiques en IA31. »

Pour rendre ces idées plus compréhensibles, Trevor Paglen et son équipe ont créé Image-Net Roulette,un réseau de neurones de détection des visages entraîné sur les catégories de personnes d’ImageNet. Vous faites face à sa caméra et celle-ci détecte votre visage et le compare aux visages avec lesquels son modèle a été entraîné. Ensuite, vous sont présentées les catégories auxquelles le réseau pense que vous appartenez.
J’ai été personnellement reconnue par le système comme psycholinguiste, non-fumeuse, copilote, colocataire, schizophrène, divorcé, veuf, grammairienne, hôtesse de l’air, passagère, extravertie, plouc, âme sœur, grande sœur, petit frère, gnangnan, hypnotiseuse, personne ordinaire, pessimiste, call girl (quand je tenais mon téléphone de façon évidente), dormeuse, somnambule, utilisatrice et, si je commençais à sourire, le système me voyait en carriériste et en sociologue. Il y avait une femme devant moi, elle avait un grand front mais des cheveux longs et épais, elle a été décrite comme skinhead. Lorsque je raconte cela à Paglen et Crawford, cette dernière s’exclame : « J’ai eu experte aux échecs hier ! » et, se tournant vers Paglen : « Tu as eu suprémaciste blanc, toi », ce qu’il ne peut que confirmer d’un hilarant « en effet ».
« La grande majorité des modèles de reconnaissance faciale sont standardisés, de sorte que la majeure partie de la vision par ordinateur, même réalisée par des entreprises, est basée sur les mêmes modèles », poursuit-il. Et, alors que je m’interrogeais sur le nombre de personnes qui ont effectivement accès aux modèles utilisés en interne chez Google ou Facebook, Kate Crawford s’alarma : « Si l’on additionne les effectifs techniques des Big Five, je pense que l’on n’est même pas à cent mille personnes. Et ce sont ces personnes qui créent des systèmes de visualisation qui influencent la vie de milliards d’autres personnes ».
Six décennies après les premières expériences en matière de vision par ordinateur, la question est maintenant de savoir comment nous avons entraîné les machines à nous voir. Comme les images opératoires sont pour la plupart invisibles, qu’elles n’atteindront jamais nos yeux parce qu’elles n’ont même pas besoin de prendre la forme de ce que nous appelons images pour accomplir la mission pour laquelle elles sont collectées, nous ne pouvons que nous demander, avec Trevor Paglen : « si l’IA est entraînée sur des images comme celles-ci, puis utilisée, comment l’IA nous entraîne-t-elle à son tour ? »
Quelques jours après l’annonce du fait que l’UE envisagerait la création d’un « réseau de bases de données de reconnaissance faciale des polices nationales32 », cette réflexion ne fait malheureusement que commencer.
Lorsque je repasse devant Image-Net Roulette une heure plus tard, le système me reconnaît : « grammairienne, non-fumeuse, psycholinguiste » affiche-t-il. Il encadre également une partie vide du mur derrière moi et l’affuble de la catégorie « peintre ».

1 Tel que présenté sur le site web de l’Institut national des normes et de la technologie, https://www.nist.gov/programs-projects/face-recognition-technology-feret
2 Idem.
3 Trevor Paglen lors de la présentation de l’exposition.
4 Gary B. Huang, Tamara Berg, Marwan Mattar, Eric Learned-Miller, « Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments », octobre 2008.
5 https://megapixels.cc/brainwash/
6 Kate Crawford, entretien avec l’auteure, Milan, 11 septembre 2019.
7 Trevor Paglen, « Invisible Images (Your Pictures Are Looking at You) », The New Inquiry, 8 décembre 2016, https://thenewinquiry.com/invisible-images-your-pictures-are-looking-at-you/
8 « Dans mon premier travail sur ce sujet, Eye/Machine (2001), j’ai appelé ces images ‘images opératoires’, des images faites ni pour divertir ni pour informer. Ce sont des images qui ne représentent pas un objet, mais qui font plutôt partie d’une opération ». Harun Farocki, « Images fantômes », Public, n° 29, Nouvelles localités, 2004, p. 17.
9 David Hubel et Torsten Wiesel, « Receptive fields of single neurones in the cat’s striate cortex », The Journal of Physiology, 1959, n°148, p. 574-591. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2718232/
Dans l’exposition « Training Humans », Trevor Paglen et Kate Crawford présentent une vidéo de 1973 d’expériences menées sur des chatons par le neurobiologiste Colin Blakemore qui étudiait alors le développement du cortex visuel. https://www.youtube.com/watch?v=QzkMo45pcUo
10 Jerome Lettvin, Humberto Maturana, Warren McCullloch et Walter Pitts, « What the frog’s eye tells the frog’s brain », 1959, Proceedings of the Institute of Radic Engineers, vol. 47 : 1940-1959. https://neuromajor.ucr.edu/courses/WhatTheFrogsEyeTellsTheFrogsBrain.pdf
11 MADALINE (pour Multiple ADAptive LINear Elements) a été le premier réseau neuronal artificiel appliqué à un problème du monde réel. Développé en 1959 par Bernard Widrow et Marcian Hoff à Stanford, son architecture est toujours utilisée aujourd’hui.
12 « La rétine envoie très peu d’informations au cerveau ; ce que nous voyons est en fait reconstruit par notre cerveau », comme l’explique Gérard Berry dans « La photographie numérique, un parfait exemple de la puissance de l’informatique », son cours au Collège de France le 31 janvier 2018. https://www.college-de-france.fr/site/gerard-berry/course-2018-01-31-16h00.htm
13 Certaines affirmations de Lettvin, Maturana, McCullloch et Pitts ont depuis été contredites, voir : Conor Myhrvold, « In a Frog’s Eye », MIT Technology Review, 2 janvier 2013https://www.technologyreview.com/s/508376/in-a-frogs-eye/
14 Russell A. Kirsch cité dans Rachel Ehrenberg, « Square Pixel Inventor Tries to Smooth Things Out », Wired, 28 juin 2010. https://www.wired.com/2010/06/smoothing-square-pixels/
15 Woody Bledsoe, dans un essai inédit de 1976, cité dans Shaun Raviv, « The Secret History of Facial Recognition », Wired, 21 janvier 2020. https://www.wired.com/story/secret-history-facial-recognition/
16 Le transistor à effet de champ métal-oxyde-silicium — le premier transistor miniature — a en effet été conçu en 1959 et a conduit au développement massif des dispositifs électroniques que nous connaissons.
17 Woodroe Wilson Bledsoe, « A Facial Recognition Project Report », 1963, p. 1.https://archive.org/details/firstfacialrecognitionresearch/mode/2up
18 Idem, p. 2.
19 Bill Richards, « Firm’s Suits Against CIA Shed Light on Clandestine Air Force », The Washington Post, 12 mai 1978. https://www.washingtonpost.com/archive/politics/1978/05/12/firms-suits-against-cia-shed-light-on-clandestine-air-force/a8d77856-6920-40a4-a430-13b9c9171245/
L’information n’a été ni confirmée ni démentie par la CIA : https://www.muckrock.com/foi/united-states-of-america-10/relationship-of-king-hurley-research-group-and-cia-10656/
20 Le fils de Woody Bledsoe a déclaré avoir vu son père mettre le feu à un certain nombre de documents, dont certains portaient la mention « Classé secret », en 1995 ; voir Shaun Raviv, « The Secret History of Facial Recognition », art.cit. Le reste de ses archives est conservé au Briscoe Center for American History de l’université du Texas à Austin.
21 Trevor Paglen lors de la présentation de l’exposition.
22 Woodroe Wilson Bledsoe, « A Facial Recognition Project Report », 1963, Bibliographie, p . I.
23 Voir par exemple le manuel Kubark Counterintelligence Interrogation, maintenant déclassifié (depuis janvier 1997), daté de juillet 1963. https://nsarchive2.gwu.edu//NSAEBB/NSAEBB122/index.htm#hre
24 Patricia Nilsson, « How AI helps recruiters tracking jobseekers’ emotions », Financial Times, 28 février 2018.https://www.ft.com/content/e2e85644-05be-11e8-9650-9c0ad2d7c5b5
25 Kate Crawford lors de la présentation de l’exposition.
Sur cette question précise, voir L.F. Barrett, R. Adolphs, S. Marsella, A.M. Martinez, et S.D. Pollak, « Emotional expressions reconsidered: Challenges to inferring emotion from human facial movements », Psychological Science in the Public Interest, 20, 2019, p. 1-68.
26 Trevor Paglen lors de la présentation de l’exposition.
27 http://image-net.org/about-overview
28 Crawford et Paglen lors de la présentation de l’exposition.
29 Aude Launay, « Algocurating », 02 n°80, hiver 2016-17. https://www.zerodeux.fr/interviews/le-curating-algorithmique/
30 Kate Crawford, entretien avec l’auteure, Milan, 11 septembre 2019.
31 Idem.
NB Toutes les citations suivantes sont des extraits de la conversation qui a suivi mon entretien avec Trevor Paglen et Kate Crawford à Milan.
32 Zach Campbell, Chris Jones, « Leaked Reports Show EU Police Are Planning a Pan-European Network of Facial Recognition Databases », The Intercept, 21 février 2020. https://theintercept.com/2020/02/21/eu-facial-recognition-database/
Kate Crawford | Trevor Paglen, Training Humans, Fondazione Prada Osservatorio, Milan, 12.9.2019 – 24.2.2020
Table-ronde avec Kate Crawford et Trevor Paglen modérée par Aude Launay mercredi 8 avril 2020, 19h, auditorium du Jeu de Paume, Paris. > Reportée, date à confirmer
Image en une : Sur la table : UTKFaces, Zhifei Zhang, Yang Song, Hairong Qi, 2017. Au mur : Selfie Dataset, Mahdi M Kalayeh, Misrak Seifu, Wesna LaLanne et Mubarak Shah, 2015. Vue de l’exposition Kate Crawford | Trevor Paglen: Training Humans, Osservatorio Fondazione Prada. Photo : Marco Cappelletti. Courtesy Fondazione Prada.
- Publié dans le numéro : 93
- Partage : ,
- Du même auteur : Thomas Bellinck, Christopher Kulendran Thomas, Giorgio Griffa, Hedwig Houben, Pamela Rosenkranz,
articles liés
Iván Argote
par Patrice Joly
Laurent Proux
par Guillaume Lasserre
Diego Bianchi
par Vanessa Morisset

