Algocurating
“In 1957, Robert A. Dahl succinctly defined the concept of power as follows: ‘A has power over B to the extent that he can get B to do something that B would not otherwise do.’ […] The most direct manifestation of power is coercive force or ‘hard power’. […] Imprisonment. A gun pointed at you, or even the knowledge or fear that your opponent has a gun. […] Situations where you, B, face the direct, negative consequences from your possible noncompliance with A. ‘Soft power’, by contrast, lets B do what A wants because B deems it attractive (thus beneficial) to be like A. This is the power of seduction, persuasion, image, and brand. The outcome of soft power is a change of behavior of B under the influence of A, where no act or threat of force was necessary.” 1
“Any technological process involves a degree of abstraction. […] The abstraction implies a relationship where the compliance of the user with this abstraction benefits the provider to the point where A gets B to do something it wouldn’t otherwise do.” 2 It’s behind abstraction that we hide when we mention the cloud, networks, but also, for example, food-processing or pharmaceutical industries, as it can be a way to conceal something as much as a way to simply refuse to see this thing.
Algorithms are abstractions with concrete results.
Facebook users generate about 4 millions likes every minute,3 and more than 7 billions a day. 49% of these users like a Facebook page to support a brand they like.4 (Can we think of, for a second, what can mean “support a brand one likes”?)
Let’s remember quickly how all this works.
A large part of our daily life is, as of now, mediated by artificial intelligence systems —the intelligence of which depends on ingesting the most extensive possible quantity of data about us— be it when applying for a job, a new health insurance or a loan, be it when we buy a train ticket, a book or new shoes online, when we order a Uber or look for an Airbnb flat, or simply when we log on to our mailbox, to Facebook to say hi to a friend, to Twitter to keep up with the news, to our bank website for a transfer, without forgetting when we contact the customer service of our phone company… (Artificial intelligence systems are not only connected to the Internet, which is a fact we tend to forget.)
One could think of these algorithms we commonly interact with (“the indexers, the recommendation and the visualization algorithms that offer users a sense of control over these data. Yet the same algorithms that make the cloud usable are the ones that define a ‘user’ as that ever growing stream of data to be analyzed and targeted” 5) as processes hovering in between hard power and soft power: hard as they clearly limitate our actions, such as ‘liking’, soft as we comply volunteerly to them, such as when ‘liking’, again. As states Matteo Pasquinelli, “Deleuze registered this shift that marks the passage from Foucault’s disciplinary society to the ‘societies of control’ based on ‘data banks’. ”6 And indeed, “platforms allow us to act in datafied, algorithm ready ways”, their rules being “enacted through counting, informed by what counts and determining who counts” reminded us Carolin Gerlitz during the last AoIR conference7. So yes, algorithms curate what we see everyday on our news feeds, ‘decide’ how long the content is shown and to whom. For them, we are a set of data. No more no less. For instance, “consider the credit card. There are often no preset spending limits associated with the card, and because a computer determines whether a particular transaction is fraudulent by comparing it to the charges the spender usually makes, a cardholder does not even have to worry if someone steals the card. […] Somewhere, a computer is calculating the impact of each spending decision and adjusting to it in real time, and, in turn, the cardholders adjust, too. ‘You’ are a set of spending patterns.”8 Algorithms are just a way to organize and process those data which define us. They’re just sets of instructions. No more no less.
Algorithms seem to increasingly gain power over us, why? Because we empower algorithms with judging capacities9 and, in return, these judgements we have them produce influence our behavior as a self-regulation inherited from the benthamian panopticisim but, above all, from the deleuzian control stemming from the decentralization of power that we think we perceive in the network’s infrastructure. So it’s not simply a matter of a comfort that might be found in the fact of delegating our decision-making, but of a more complex structure of sending back references which operate in such a discreet way that one ends up internalizing them. Thus it’s not only the now classic issue of a filter bubble10 but that of a normalization of pratices induced by habits. So we can assume that the inferences and predictions performed by the algorithmic systems will not rationalize our behaviors but, on the contrary, as Antoinette Rouvroy explains it, will “relieve human actors of a whole series of mental operations (the representation of facts, interpretation, appraisal, justification…) which are part of rational judgment, in favor of a systematic management such as to arouse purchasing impulses.” 11 Because if “algorithmic governmentality is essentially nurtured by ‘raw data’ which are in themselves insignificant (this absence of significance being incidentally perceived as a pledge of objectivity”12, “critical decisions are made not on the basis of the data per se, but on the basis of data analyzed algorithmically”13. Algorithms are in fact filters and, like data, in themselves do not directly produce significance. It is the way they are used and, above all, the way their results are interpreted that matters. “So the usefulness of each datum depends on the quantity of the other data with which it is liable to be correlated, more than on its information density. Even very low-density information data (the anonymous data which, individually, are thoroughly trivial and meaningless) acquire usefulness when their quantity increases.” 14 Just like data, algorithms are what one does with them, they’re defined by their use. The critical questions that arise then are, of course, who uses them but also who devises them? As Kate Crawford notes, 80% to 90% of the people working in these engineering departments (which mainly divide into seven major companies designing AI systems over the world) are men, mostly white and from a wealthy background, therefore “they look like each other, think like each other”15 in teams with underrepresented minorities. And, as “an algorithmic system is not just code and data but an assemblage of human and non-human actors—of institutionally situated code, practices, and norms with the power to create, sustain, and signify relationships among people and data through minimally observable, semiautonomous action”16, the urgent issue to address is how to overcome the algorithmic governmentality17 per se, and look as much at our relation to it as to it as the core problem.
This is where artists intervene. By asking what is at stake when we delegate a choice to a machine, in particular in a field as definitional of man as art (even though this seems to be a perfectly direct consequence of the content curating of our Twitter, Facebook, Instagram and other feeds), they remind us that the general quantification that governs any algorithmic system is first and foremost a highly criticizable idea. The fact that Cameron MacLeod relies on an algorithm created by him to designate the artists who will feature in the group shows he organizes, or that Jeremy Bailey uses one to determine the works that will be presented in exhibitions that he describes as personalized to the tastes of a single viewer, well, they both add to curating—as artists—a machine dimension, which opens up a new field of prospects that are as technological as they are philosophical.
1 Metahaven, Black Transparency, The Right to Know in the Age of Mass Surveillance, 2015, Sternberg Press, p. 121.
2 Metahaven, op.cit., p. 127.
3 2015 data. Source: http://wersm.com/how-much-data-is-generated-every-minute-on-social-media/
4 2013 data http://marketingland.com/why-do-consumers-become-facebook-fans-49745
5 Tung Hui-Hu, A Prehistory of the Cloud, MIT Press, 2016, p.111.
6 Matteo Pasquinelli quoting Gilles Deleuze, “Postcript on the Societies of Control”, October n°59, Winter 1992, tr. Martin Joughin from the original French version published in L’autre journal, May 1990, in his article “The Spike : On the Growth and Form of Pattern Police”, in Nervous Systems, Spector Books, 2016, p. 283.
7 Association of Internet Researchers annual conference held in Berlin, Oct 5-8 2016. See the discussion between Carolin Gerlitz, Kate Crawford and Fieke Jansen entitled “Who rules the internet?” held on Oct 6: http://www.hiig.de/en/events/aoir-who-rules-the-internet/
8 Tung Hui-Hu, A Prehistory of the Cloud, op.cit., p. xv.
9 “The notion of the algorithm is part of a wider vocabulary, a vocabulary that we might see deployed to promote a certain rationality, a rationality based upon the virtues of calculation, competition, efficiency, objectivity and the need to be strategic. […] The algorithm’s power may then not just be in the code, but in that way that it becomes part of a discursive under- standing of desirability and efficiency in which the mention of algorithms is part of ‘a code of normalization’ (Foucault, 2004, p. 38)”. David Beer, “The social power of algorithms”, in Information, Communication & Society, 20:1, 1-13, p.9. http://dx.doi.org/10.1080/1369118X.2016.1216147
10 Eli Pariser, The Filter Bubble: What the Internet Is Hiding from You, New York, Penguin Press, 2011. It’s Pariser who first theorized this hyper-personalization of the web, i.e. of the search engines, social networks and news feeds, soon after Google started the process by not outputting the same results for the same input of research terms for researches conducted by different persons, at the end of 2009.
11 Antoinette Rouvroy in an interview with Marie Dancer, TANK, n°15, Winter 2016.
12 Antoinette Rouvroy, “Le gouvernement algorithmique ou l’art de ne pas changer le monde”, 2016, unpublished.
13 Frank Pasquale, The black Box society: The secret algorithms that control money and information. Cambridge, Harvard University Press, p.21.
14 Antoinette Rouvroy, “Des données et des hommes, droits et libertés fondamentaux dans un monde de données massives”, rapport à destination du Comité Consultatif de la Convention pour la protection des personnes au regard du traitement automatisé de données personnelles du Conseil de l’Europe, augmented version, p. 6.
15 “Artificial Intelligence is Hard to See: Social & ethical impacts of AI”, Kate Crawford in conversation with Trevor Paglen, Berlin, October 7, 2016. https://www.youtube.com/watch?v=kX4oTF-2_kM
16 Mike Ananny, Kate Crawford, “Seeing without knowing: Limitations of the transparency ideal and its application to algorithmic accountability”, new media & society, 2016, p. 11. http://journals.sagepub.com/doi/full/10.1177/1461444816676645
17 A term coined by Antoinette Rouvroy.
An interview with Cameron MacLeod
It’s already been three years that we’ve been witnessing group shows happening in Sweden, Norway or Lithuania for which the artists haven’t been chosen by a curator but by an algorithm. We discuss this program, named Curatron, and its implications, technical as well as ethical, with its creator, the Canadian artist Cameron MacLeod.
If a human curator uses Curatron, is he still a curator in your opinion? Is Curatron more a tool for curators or a sort of algorithmic curator on its own?
Well, it depends on how someone defines a ‘curator’.
Someone has to initiate an exhibition using Curatron, which means there is at least an initiator. The person using Curatron makes an offer to the art community and that offer includes the parameters on how the group selects itself as well as all the resources that are provided to the artists: space, funding, marketing, etc. So there are many choices that need to be made before the open call is published and afterwards, depending on the offer. One might think that having the artists participate in the selection process removes the definition of the curator, whereas others would disagree and see the creation of the offer and the management of the show as a curatorial act. It would also depend on how the initiator defines himself or herself, I don’t have a position on whether using Curatron could be considered curatorial or not, but if it could be considered a curatorial act, it could also be considered a tool for curators.
How do things happen during the setting up of the show: do the artists decide on everything by themselves, together, or do they rely on the curator usually working in the exhibition space where the show takes place?
A group is thus selected through an open call ; how the show is put together could be the decision of the group after the selection, or of the curator: in either case, I usually define it in the proposal, so the artists know what they are applying for. For instance, I could say that the selected group will have to make a singular work together, which most people would think of as a curatorial act.
In the past, we have had all sorts of configurations in terms of what level of participation the artists had in producing the show. I used to interact a lot with the artists in the development of the show, but I have been increasingly removing myself from this process and giving them more control over the output. That said, I always give them the resources needed in order to cover what they want to do: they can choose whether they want installation technicians or not, what level of participation they want from me in curating the show, if they want to collectively hire a writer or not. This has been my strategy, but anyone else administrating a Curatron show could choose to have more curatorial control over the group, which is fine as long as it is stated in the open call. There is an almost infinite number of scenarios of the use of Curatron.
Where does that idea come from? What inspired you to create Curatron?
My time living in the Canadian Arctic in 1999 formed the foundation of my current interests which led to the development of Curatron.
When I became more acutely aware of the shift from a hunting and gathering society to an industrialized nation that the Inuit people had undergone in a relatively recent period of time, I also became more interested in this transition in a more shared history, in a global context over a longer period of time. As we know, the advent of agriculture brought sedentarity, increased the divison of labour, shifted concepts of private and public property, led to capital accumulation, class division and developing urbanity. These rather ancient origins of development and the cultural repercussions that emerge from such a technological innovation became a driving interest in my work/life. I wondered if it was possible to reverse the processes to acquire some of the same social frameworks that existed within hunting and gathering societies and still maintain an advanced technological infrastructure.
I then joined a specialized MFA in Art in Public Realm in Stockholm where I was introduced to relational aesthetics, intellectual property, institutional critique…There I focused on developing technologies that tried to achieve this perfect techno-primitivist equilibrium and I realized that the Internet as a production system shares some principles with hunting and gathering societies.
The Stone Age Electronic Calculator is a seminal project in my practice which articulates most of my interests. It is a collaborative wiki website where a community of contributors produces a manual that explains how to make a calculator in the woods, with no tools. This project attempts to reflect on the possibility to create a system of technological production that allows for public ownership and production over the entire computational infrastructure while maintaining a hunting and gathering lifestyle.
After I graduated, I co-founded Platform Stockholm, a studio collective with a hundred and ten artists. I started to make online systems to crowdsource administrative decisions to the artists in that collective: for instance, to vote to allocate part of the monthly budget. After running Platform for a year, I moved to Norway to work for a software company doing some of the same things I did in my art practice and I ran Platform remotely. I learned more about the development of sophisticated online systems during this time and, when a space for a gallery became available in the Platform building, what should happen next was almost obvious. I tried to give the artist collective control on the first show, so the artists in the building had voting power over the artists in the show, but I realized that it would be possible or more interesting for the artists to vote on themselves, and Curatron was born.
When you describe the selection process, you say that Curatron is “more complex than a simple voting system” and that it “ ‘decides’ on the final group of exhibiting artists based on the patterns of connection between selected artists that emerge in the peer-evaluation stage. In other words, if one artist is selected by all his or her peers, this does not guarantee participation in the exhibition. Rather, the software tests something like collective taste or sensibility by recognising when artist groupings appear across different selection proposals.”
First, can you tell me more about those ‘patterns of connection’: how would you characterize them and how did you choose them?
Then, I’d like you to explain the role of this notion of ‘collective taste’ in the making of an art show and to what extent Curatron can also be seen as a highly critical tool in regard to the general profiling and microtargetting strategies now in use in almost every area of business and politics. 1
The patterns of connections are built from the way we place value on the selections between people, which is based on some simple logic aiming at achieving a ‘collective choice’. Not that I have succeeded in developing a pure form of ‘collective choice’ but it is the attempt to design such a choice which is perhaps the most concise motivation in the development of the project.
Here is a breakdown of the process:
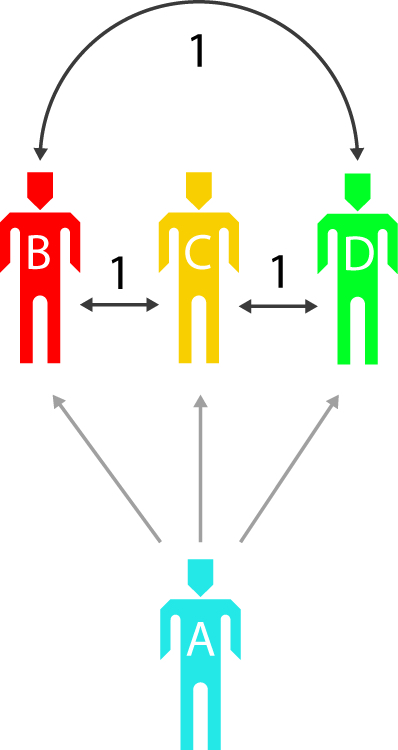
- Self Selection
When one person selects another person, a value is created between them.
- Group Selection
When each person selects several others, they create value between themselves and all those people, but they also create values between those people, independently of themselves.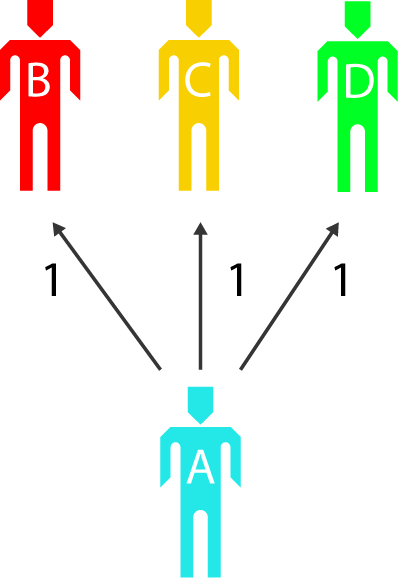
The values of self-selection and group selection are weighted differently. At the moment, you create more value between people by selecting them to be part of a group than you do by choosing to associate yourself with them. These values used to be weighted evenly, but we discovered over time that the way a user thinks about his or her own practice in relation to another is less accurate than his or her perception of how other practices relate to each other.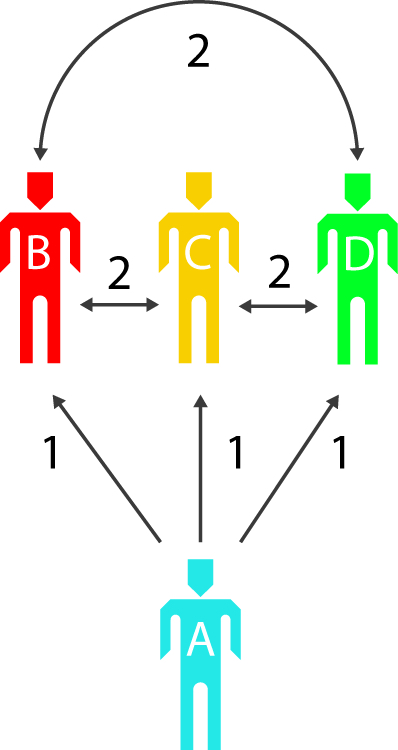
Once all the applicants have created groups (producing value between practices), we run a very basic algorithm that compiles all the value-data and then outputs one final group.
For example: we send out an open call for a show with four artists plus the applicant. We let the users know that the best way to optimize selection is choosing artists who they feel have similar practices to their own: perceived similarity allows for more overlapping choices between applicants, as shown in the diagrams. Then we calculate every possible combination of five from the applicant pool: the group with the highest value is selected for the exhibition. We call this number group cohesion. It isn’t based on the most popular artists, but on the most popular group, in which relationships between practices are perceived to be the strongest by the applicant pool. What we are trying to do is find the group that defines a significant trend of interest in the applicant pool.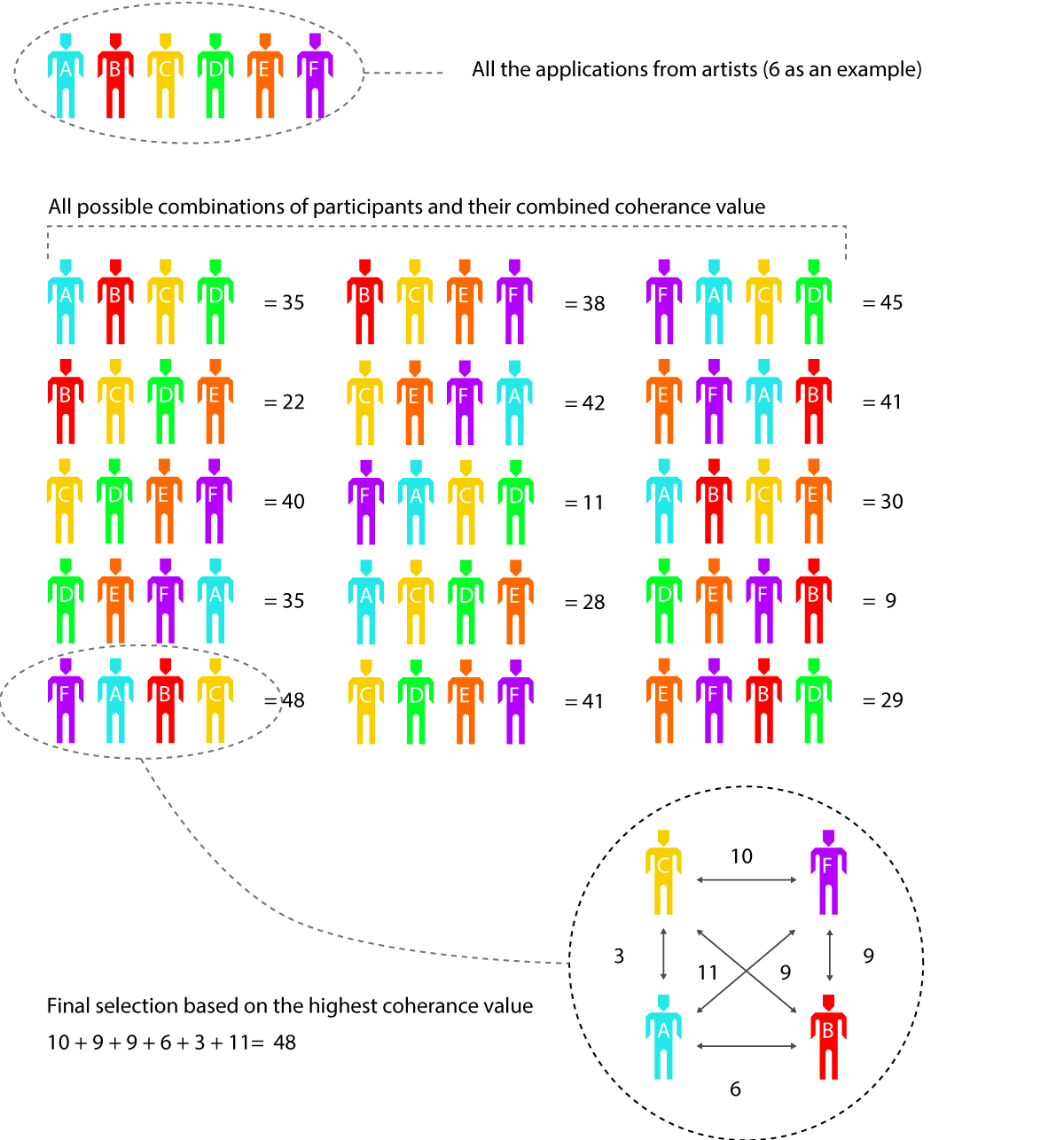
Curatron provides an alternative methodology to the traditional open call while it can be seen as a type of open call. Rather than a board of people or a singular person that reviews the applications, the applicants review the applications, which requires a completely different process. We need to make the applications of the artists visible to each other so they can make their selection, which creates new circumstances for social engagement. The social engagement happens between the participants applying, the ones selected, the managing staff of the particular venue, the people who view the exhibition both physically and virtually, the software developers, the granting bodies and me.
So collective taste not only functions as a context for the curation of the show but also presents an alternative process which opens up new forms of social engagement outside of just the selected artists. An exhibition produced with Curatron can look indistinguishable from any other exhibition produced through other means although the process of setting it up implied new work methods: the artists are selected under completely different terms, so the relationship to the curator is somewhat shifted, opening up for a different structure within which to work.
Much of my previous work explore contentious areas in emerging technology trends, mostly in relation to emancipatory ideals within the collective ownership in shared technological infrastructure. Challenges surrounding open source production, online exchange processes, issues of public and private data and automation are more my history and current focus. I explore possible obstacles or opportunities on the way to a collectively owned crowdsourced utopia and the work is not meant to be overtly critical but could be read critically.
It might be a far reach though to make a connection between Curatron and microtargetting. They both use social analytics and pattern recognition to present a result but…
I was rather thinking about the fact that trying to define a somewhat ‘collective taste’ could possibly be a clear opposition to microtargetting and to the way most of the web functions today, aiming at a ‘personalized’ experience for the user/consumer/target.
The way Curatron works now uses one definition of collective taste which people may or may not subscribe to, i.e. defining the most popular group in the application group. The logic that we use to define it could be contested but this definition is the best that I could think of. The way we define collective taste is embedded in the algorithm that we use (self selection, group cohesion etc.):self-selection, for instance, represents the value in between the selector and the selected, an individual’s perception of his/her own practice in relation to others; group cohesion represents the value between the selector and those he/she has selected, i.e. an individual’s perception of others’ practices in relation to the others. When we calculate the final group, we collect individual tastes into a group decision and place value on some definitions of taste over others. This algorithm could take many forms and each form is a hypothetical definition of what collective taste could be.
Collective taste, the way I have designed it, has all sorts of potential use cases. It could be implemented as an oppositional strategy for organizing people’s data feeds and dispel misinformation that may come from unwanted solicitation. But it wouldn’t do anything to reduce data feed tampering in its present version, although it wouldn’t have to in order to be perceived as critical of microtargetting.
Thus what’s at stake behind your way of thinking ‘collective taste’?
Presently, collective taste is an ideal in Curatron, something I strive for that may be impossible. It is in its infancy and a rather clunky form of measuring tastes from many persons. It presents a singular idea of what a collective taste is, based on how I think the algorithm should reflect it and the means I have to construct it. It does, however, present a real working strategy for a digitally supported collective intelligence within an undefined art community. Over these first three years, I have tried several strategies to remove my own authorship from the project through outsourcing various tasks, but the next step will be an attempt to attain a further level of removal, programatically: to remove myself entirely and enable a complete collective control over its development would be the ultimate goal of Curatron. Collective intelligence in this context is as much a culture as the digital system that supports it is.
So do you see Curatron as one of your works as an artist or more as a curatorial project or both or maybe you don’t care about pigeonholing it?
Both really, and I am not so concerned with defining what Curatron is. I definitely consider it as part of my practice and I define myself as an artist if someone asks my profession. I do work a lot with curation and I run my own gallery but this has somehow evolved out of my art practice… I am asking the same questions in these other fields as when I am making art, but I do think Curatron can exist as an artwork or maybe as an artwork employing curatorial strategies. I don’t want my definition of what art is to limit other people’s understanding of what Curatron is, though.
Are there other similar projects which you could connect Curatron to?
Well, there was a group in Oslo, Tidens Krav, that had some pretty outside of the box application processes, for example they let people apply via telephone message for group shows.
And, as you know Jonas Lund made an algorithm that gave him instructions on how to make art exhibitions related to a particular gallery, but he works on hacking infrastructure in different ways than I do. These two references are the people I know that are doing similar things as Curatron in an artistic context, but in the software world, the closest thing to Curatron I could think of would be Tinder 1.0, since it was very simple and also placed value between users and not on them.
1 See, for instance, The Power of Big Data and Psychographics, Alexander Nix’s presentation at Concordia Summit last September where he exclaimed: “my children won’t certainly ever understand what mass communication is”. Nix is CEO of Cambridge Analytica, a company which elaborates communication strategies for the electoral process
based on data mining and data analysis. It became known in 2015, while working for Ted Cruz, then it worked for Donald Trump’s campaign in 2016. The British company also took part in the Brexit referedum, aiming at convincing voters to leave the EU, and it is said to have been approached by Marine Le Pen.
https://www.youtube.com/watch?v=n8Dd5aVXLCc (Thanks to Hannes Grasseger who broadcasted this video during Bot Like Me, the symposium held at CCS in Paris, on December 3, 2016.)
An interview with Jeremy Bailey
For ten years now, Jeremy Bailey has been haunting the free spaces of the Internet, from Youtube to Tumblr and the advertising spaces which are nibbling away at the edges of content, i.e. “public” spaces held by private companies. So there are free spaces insomuch as they can be filled, but how free exactly?
If “much of the cloud’s data consists of our own data, the photographs and content uploaded from our hard drives and mobile phones” in an era when user-generated content is dominating the content available online, and when “the cloud is, most obviously, our cloud (this is the promise of the ‘I’ in Apple’s ‘iCloud’, or to use an older reference, the ‘my’ in ‘mySpace’)”1, they are nevertheless very clearly controlled by moderators, human and algorithmic alike, of platforms and sites to which we transfer them. Thus far there is nothing particularly surprising, and it is absolutely the same in the public space, itself governed by laws (like prohibiting people from walking about in the streets naked, at least in France). But these controls go well beyond any mere verification of content within the limit of everything that does not harm others, all the more so because they are not for the most part produced by democratic state agencies—and here there is already plenty to discuss—but by the same private companies which thus hold these spaces of “expression”, on bases which are nothing if not opaque.2 It is this promise of the “I” that we are going to discuss here with the one who has accustomed us to delivering truths in some extremely hilarious guises, be it when he rebels against the total allpowerfulness of curators in the art world (which shall certainly remind us, albeit from afar, the ‘content curators’ who are rife on the Internet): “Curators, they bring all the best stuff other people have worked hard to make together in one place and they take credit for it” (Nail Art Museum, 2014), and against the extreme narcissism generated by the web 2.0: “Soon we will wear data like fashion” (The Web I Want, 2015). So with Jeremy Bailey we come back to his pivotal project, The You Museum, which is presented as “a platform for delivering personalized exhibitions in banner ad spaces across 98% of the Internet using remarketing technology”, namely those spaces into which advertisements are slipped for sites that we have just visited. The targeting of the tastes of museum “visitors” is established by way of a very simple questionnaire to do with their personality (fun and energetic or reserved and measured), types of forms (organic and curvy or geometric and pointy) and their preferred objects (small and discreet or big and bold), and it is then possible, by clicking on the box showing a work they like, for them to purchase it as a “souvenir” printed on a bag, mug or cushion. Precisely as in an irl museum.![]()
The You Museum has now been running for two years. How is it doing? If we were to compare its activity to that of a more standard “brand”, what kind of brand would it be, in terms of audience reach?
It’s going great, just under 4,000 people have signed up, it has received almost 40,000 visitors, and has served over 10 million banner ads. Things have slowed down a bit but there’s still a steady stream of people trying it out every month, in total I’ve spent about $8,000 on the project and continue to sustain it based on positive feedback from new audiences.
Many brands use the same technology as The You Museum but none of them are really self-reflective about it in the same way. I suppose, if there was a brand to compare it to, that it would be very self-aware and self-critical. Maybe Patagonia? They have these great ads that urge you not to buy their products.
That said, my reach is very small compared to major brands, but it’s huge compared to most personal brands. For me, an important component of the project and of my career in general is to reflect on what an identity means during the internet age. Today, everyone is supposed to brand themselves online. We keep hearing that brands are becoming more like people and people more like brands, but you rarely get to see this idea in an extreme form.
Speaking of audience reach, how do you name its audience : subscribers, clients, targets?
As a performance artist first and foremost, I think of them as an audience, I also think of them as users within the sphere of software as a service. My target is very broad, but is relatively constrained to those who are critically engaged with the world, who would like to see art address its subject in context instead of addressing it from a sterile white cube.
 What is exactly the product here? The objects on sale, you as an artist, art in general or the targeted consumer? Conceptually the product is the audience, they become self-aware of how they are being tracked and marketed to on the Internet. The Internet was designed as public space for knowledge sharing but has evolved into a shopping centre. The artwork exists in every user, as they perform the act of navigating the Internet, the artwork is created.
What is exactly the product here? The objects on sale, you as an artist, art in general or the targeted consumer? Conceptually the product is the audience, they become self-aware of how they are being tracked and marketed to on the Internet. The Internet was designed as public space for knowledge sharing but has evolved into a shopping centre. The artwork exists in every user, as they perform the act of navigating the Internet, the artwork is created.
So this is an artwork in the form of a commercial strategy. The items for sale mimic the ones sold in museum gift shops (mugs, cushions, tote bags…) as today, most of the big museums tend to turn into brands, producing promotional objects and souvenirs to improve their corporate identity and sustain their economy. Is your replication of this scheme also a way to address the art market’s financialization ?
Yes, exactly, the artworks are in fact virtual and I like the idea of allowing you to own a physical object similar to that of a museum giftshop, without ever really getting closer to the object itself. I also thought it was interesting to consider what would happen to these objects if they were purchased: in a way they act as an extension of the museum into the offscreen world, like a virus that spreads beyond its original host. I really enjoy when people post screenshots of the ads on social media, it extends the museum even further. I originally conceived of some aspects of The You Museum after a discussion with a friend regarding the death of the single destination website. When you think about it, there are very few static websites we visit anymore, instead we rely on algorithms and feeds to determine what’s important for us to see. The You Museum works best when it appears unexpectedly.
Under its inoffensive because overtly funny appearance, The You Museum thus relies, such as advertising and communication companies, on statistical methods to classify targets according to their so-called taste, which it mocks with a direct address of three wry questions (at the same time widely open and really limiting) to its future targets.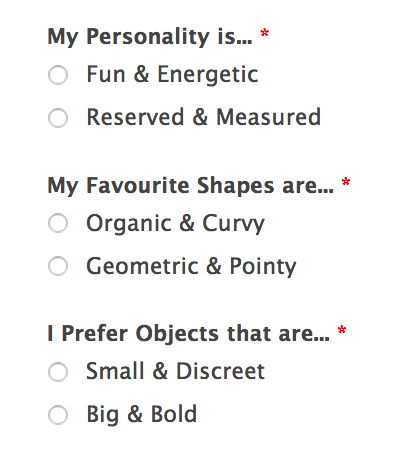
Implementing the automation of decision-making to curating as a way of datafying one of the most human and unforseeable thing such as taste in art is what makes the project so striking, as one can immediately feel this constriction of his / her own freedom in a more distinct way than when it’s about shopping more daily products, such as clothing, food or smartphones, for instance, and, of course and hopefully, translate this uncomfortable feeling to the manipulation of his / her political opinions, or any other kind of opinion. From now on, it seems one can’t escape what we could name the « fitweb », it seems that the idea of accessing the widest possible content completely turned into either a memory or a utopia, do you think of possible ways of moving past this user-centric hysterical model?
Yes it’s sad the old web died a long time ago, even most personal websites are template driven now, the utopia of the information commons is a distant memory, except maybe in a few places like wikipedia — i don’t think the story is over though. I originally conceived of The You Museum while in Istanbul, where I arrived right after the Gezi Park protests. Those protests started when the government wanted to hand one of the few parks in central Istanbul over to a developer who would turn it into a shopping mall and condo in the style of an old ottoman barracks that once stood on the site. The fact that a park, a public space designed for the community, one of the few such places in the city was being transformed into a mall and condos for the rich appropriating the style of a former empire’s military symbol… Well, the Internet is a victim of the same pressure. BUT despite everything Gezi Park is not a condo today, the protests were successful and they built a children’s playground instead of a mall. The same protest will grow on the Internet, and it will build a beautiful community. I’m sure you know adblockers are already being used by a record number of people, 25% of web users last time I checked.
You’re being very positive on this question of we, people, taking back control over the way Internet uses us, by the way we use it. So you firmly believe that the users tactics can win over the systems’ strategies. Would that mean that, on a wider scale, for you, human intelligence in its capacities to take byways could always find its way under to the coercive power of algorithms which intelligence depends on ingesting as much data about us as possible, and despite the aura of truth and objectivity this creates?
Yes, I firmly believe that as long as we commit to misuse technology it has little power over us. Make your microwave into a piano, turn your laptop into an oven… or just change your gender on Facebook to start seeing ads for Axe body spray.
1 Tung-Hui Hu, A Prehistory of the Cloud, op.cit., p.xvii.
2 http://international.sueddeutsche.de/post/154513473995/inside-facebook
- From the issue: 80
- Share: ,
- By the same author: Paolo Cirio, Sylvain Darrifourcq, Computer Grrrls, The Polyphonic History of Net Art, An Eternal Network? , Franz Wanner,
Related articles
Céline Poulin
by Andréanne Béguin
Curator’s marathon : Frac Sud, Mucem, Mac Marseille
by Patrice Joly
Émilie Brout & Maxime Marion
by Ingrid Luquet-Gad

